——基于采样和样本
- 偏差和方差的均衡:

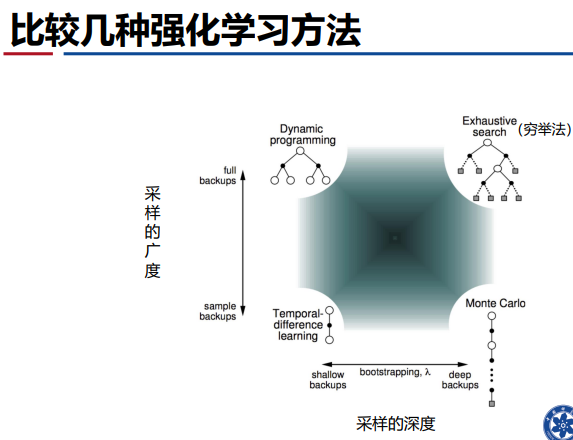
- 蒙特卡洛与时序差分的区别:


蒙特卡洛
- 定义:从完整经历中学习【采样建立知识/认知并进行统计:状态价值用多个经历片段中该状态得到的收获值的平均值表示——经历越多,模型越准确】,不用基于模型,不需要马尔可夫决策过程。(缺陷是只能被用于片段化的马尔可夫决策,要求有完整的经历片段——如五子棋有一个胜负的结尾。)
- 价值函数评估:每次尝试不同的策略pi,进行采样——更具每一步收获值用损失因子做加权获得总回报【即时回报的衰减进行加权求和】——用收获值的期望计算状态期望函数【在策略pi下,采所有样的概率平均】
- 累进式更新均值:无需记录所有数据,只需记录统计均值
 注:刚开始采样,k小——导致均值不准确;当采样越来越多,采样与均值的误差对上一步均值的修正【帮助收敛】越来越小,即逐渐收敛【大数定理】。
注:刚开始采样,k小——导致均值不准确;当采样越来越多,采样与均值的误差对上一步均值的修正【帮助收敛】越来越小,即逐渐收敛【大数定理】。 注:α—越低学习速率越慢
注:α—越低学习速率越慢
时序差分学习
- 定义:可以直接从经历的不完整经历片段中学习,通过自身引导(bootstrap)猜测经历片段的结果并不断更新猜测。
1. 时序差分算法价值函数评估:对未来下一步回报的评估【采集R、S—往前移步预估模型】


TD(λ)
- 相比时序差分,往前多看n步【变成蒙特卡洛】,n越大,看的越远,误差上界越小,收敛速度越快【但采样存在很大不确定性,看得越远,不确定性越大,方差越大】。
- λ回报:给予每一步回报一定的权重,越远,权重越小

- 有效性追踪:会根据事件发生的频率和最近发生的事件考量不同事件的权重,由此提出有效性追踪【事件越近,衰减越多、影响越大】
蒙特卡洛策略迭代
- 有模型基于V(s),无模型基于Q(s,a)
- e-贪心策略:
