生成模型概述
- Sigmoid信念网+DBN+DBM:就是一种生成式多层神经网络,并采用变分近似的方法进行训练,但是在实际应用中获得多层联合概率分布是非常困难的。

- 类别:
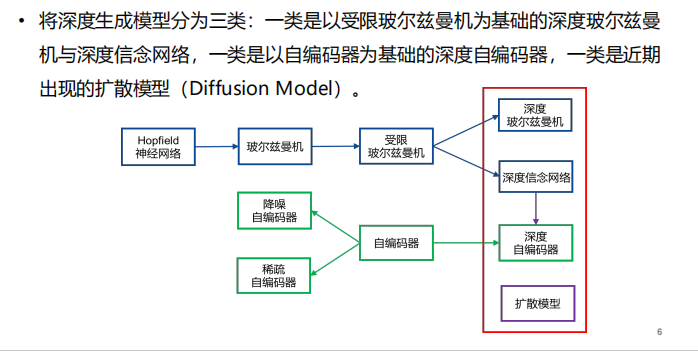
Hopfield神经网络
- 定义:一种相互连接型神经网络,也可以看作是一种单层全连接反馈神经网络


- Hebbian法:



玻尔兹曼机与受限玻尔兹曼机
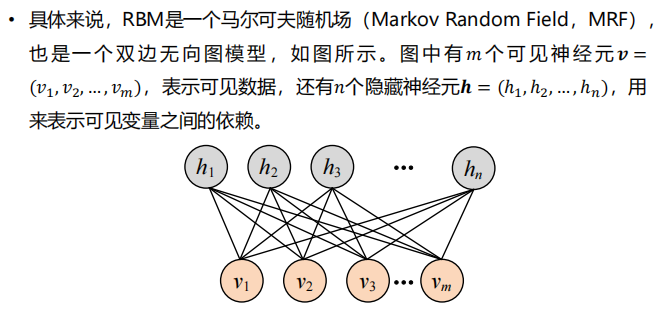
- BM:



- 受限玻尔兹曼机:的神经元之间具有双向连接,这种模型的特点是可以基于模型的抽样从未知的概率分布中学习样本的重要特征。
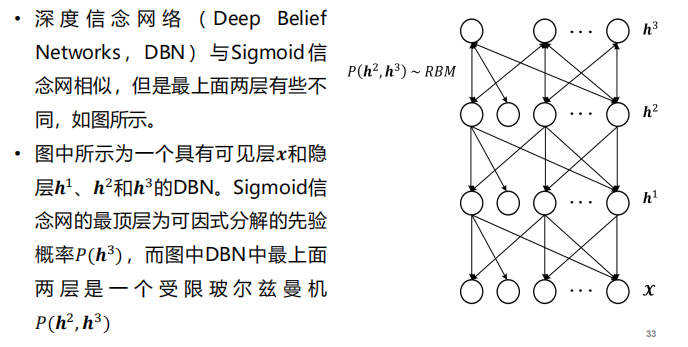
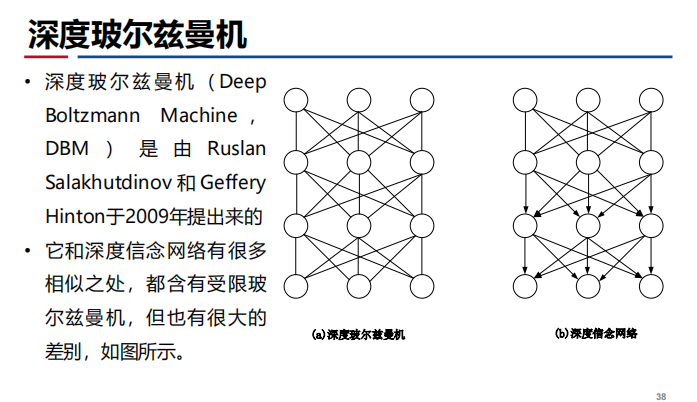
深度信念网络与深度玻尔兹曼机
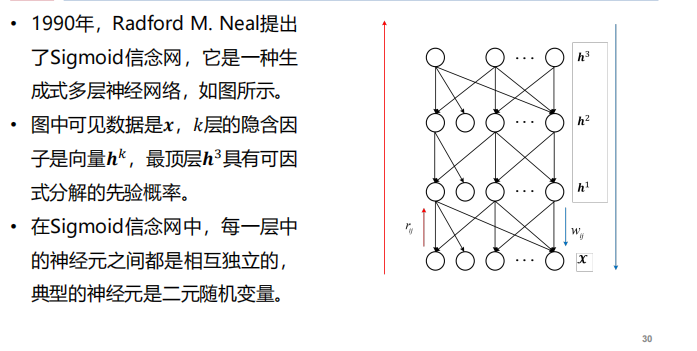
- Sigmold信念网:
- 深度信念网:
- 深度玻尔兹曼机:
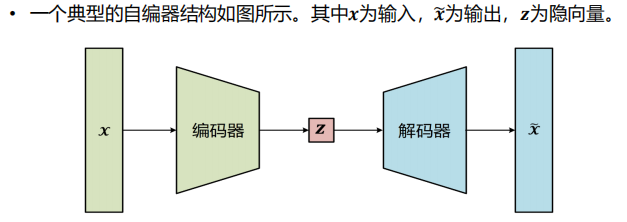
自编码器及其变种
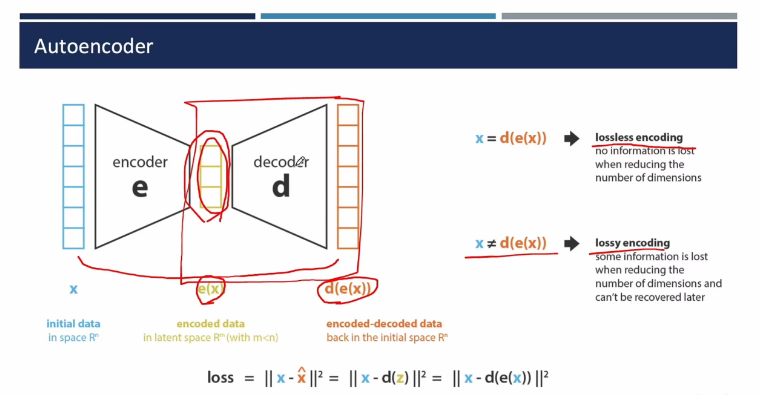
- 自编码器核心思想:使用编码器(Encoder)对高维数据进行降维并表示为一个隐向量,然后将隐向量通过解码器(Decoder)进行重构,使得原始输入与重构的输入尽可能接近。【如何尽可能压缩保留重要信息(特征),并且如何通过这些少量的重要信息还原出data(decoder)】
- VAE:学习隐空间的分布,如正态分布的参数——采样【样本】——得到向量得到原始空间
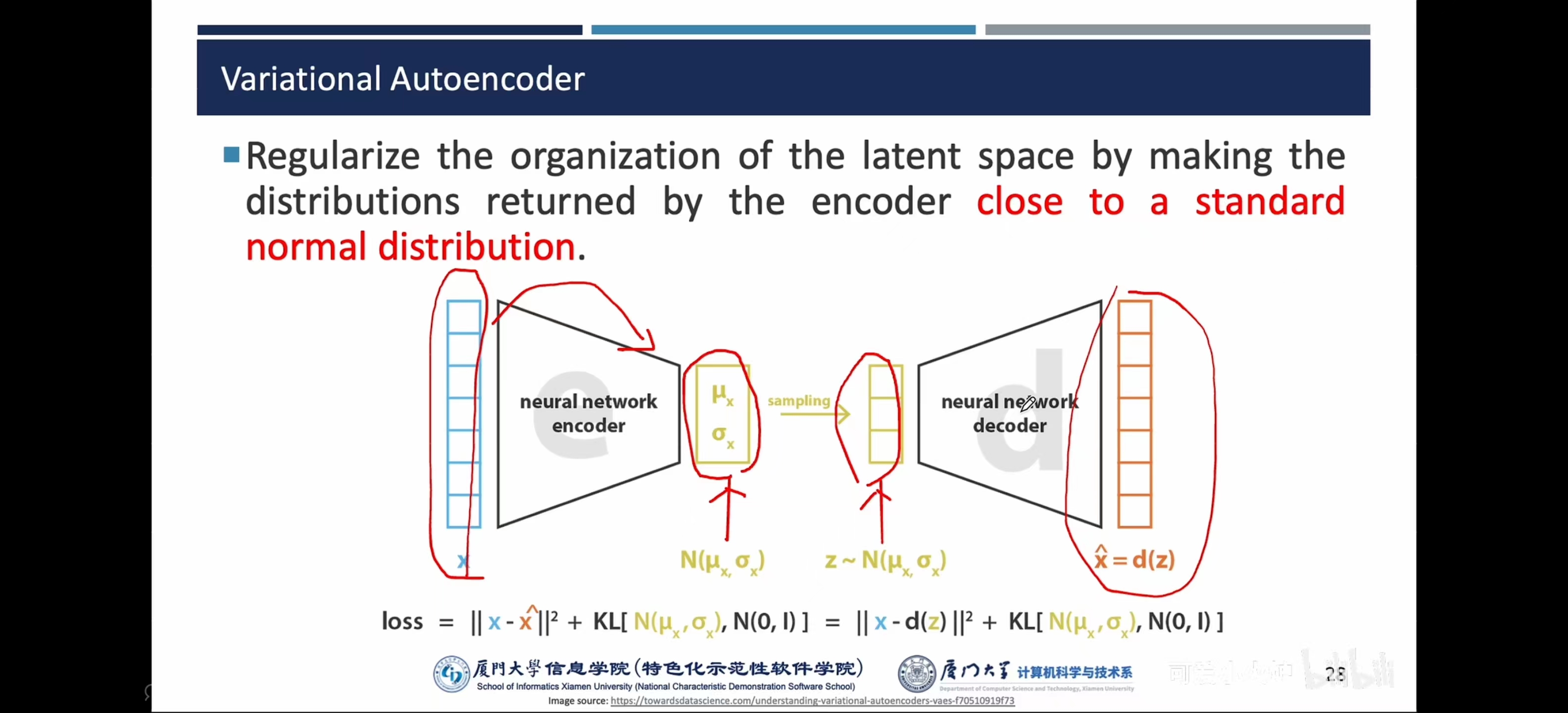 注:重建损失+隐损失
注:重建损失+隐损失
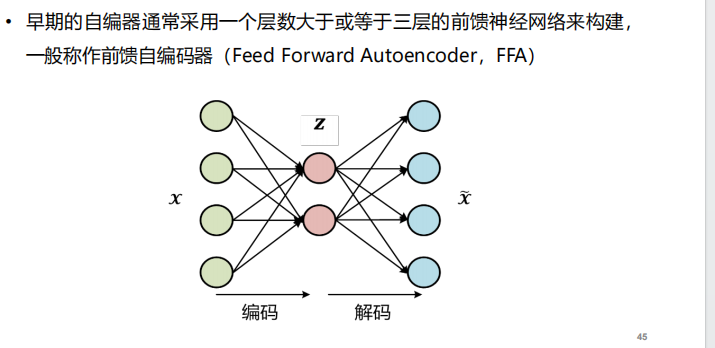
- 前馈自编码器:FFA
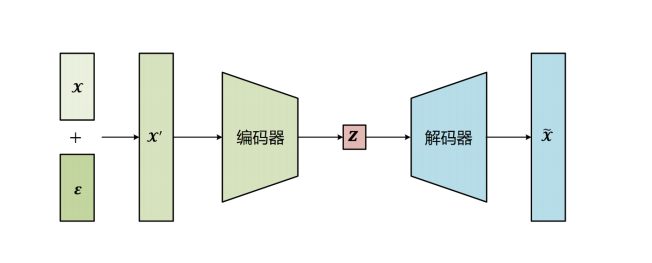
- 降噪自编码器:了防止在原始数据上进行训练时产生过拟合,加入一些噪声来训练自编码器,希望仍然能够重构出原始数据,这就是降噪自编码器。

- 稀疏自编码器:

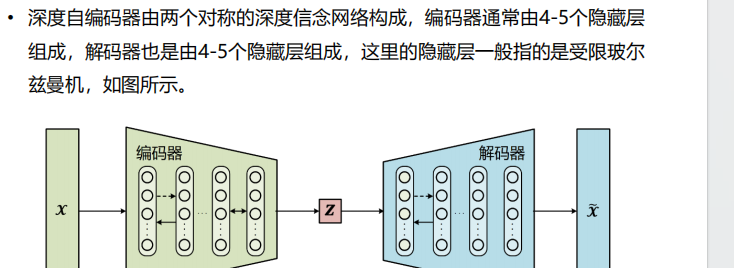
- 深度自编码器:
扩散模型
- DDPM:通过不断加噪和减噪的过程来生成的,每一次降噪更清晰【这个噪声大小尺寸和最终输出需要的图片大小一样,它不作为输入,而是需要把噪声去掉】——类似于对一块石头进行雕塑,把雕塑外面杂乱的石头去掉

 注:先预测噪声【需要告诉步骤,即当前在第几步】,再减去噪声【通过给高清图加噪(前向过程/扩散过程,减噪的过程就是生成过程或者反向过程)进行训练,让模型学习什么样的噪声让高清图片成为加完噪声的样子】
注:先预测噪声【需要告诉步骤,即当前在第几步】,再减去噪声【通过给高清图加噪(前向过程/扩散过程,减噪的过程就是生成过程或者反向过程)进行训练,让模型学习什么样的噪声让高清图片成为加完噪声的样子】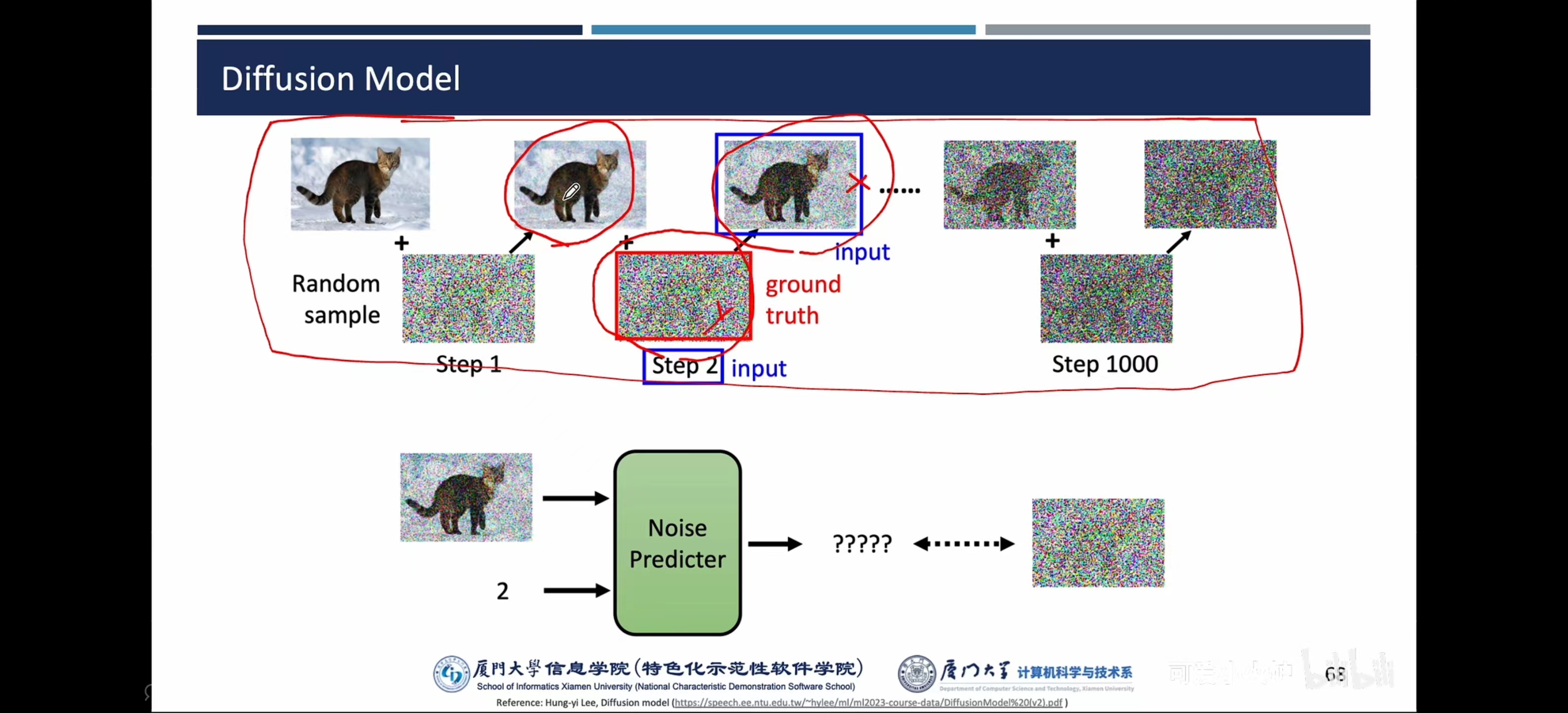

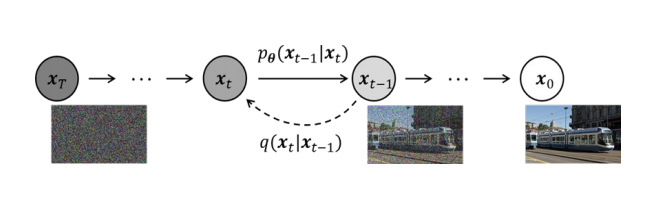

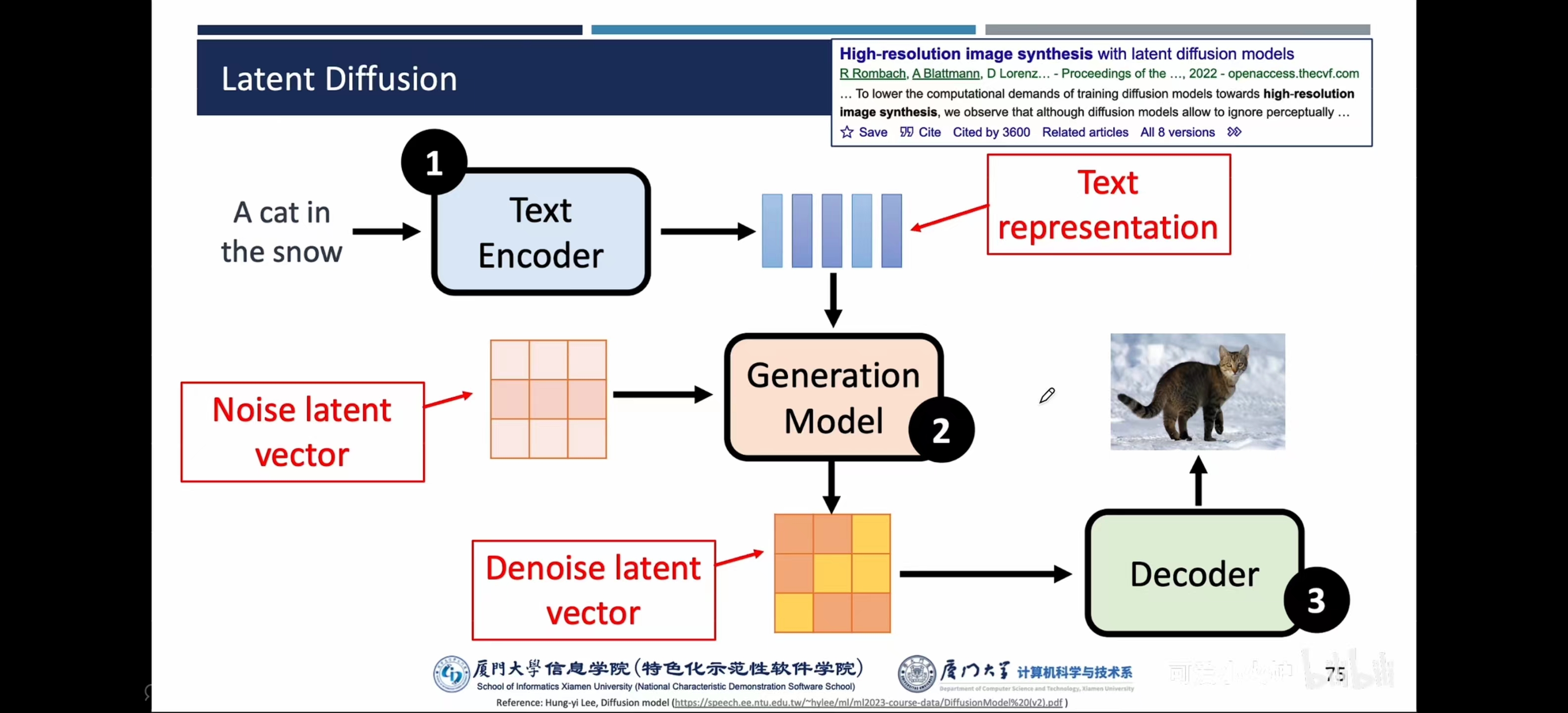
- Latent Diffusion:也可以给一段文本特征【把一句话变成语义向量】,对其进行降噪,得到干净特征后,用decoder还原成照片
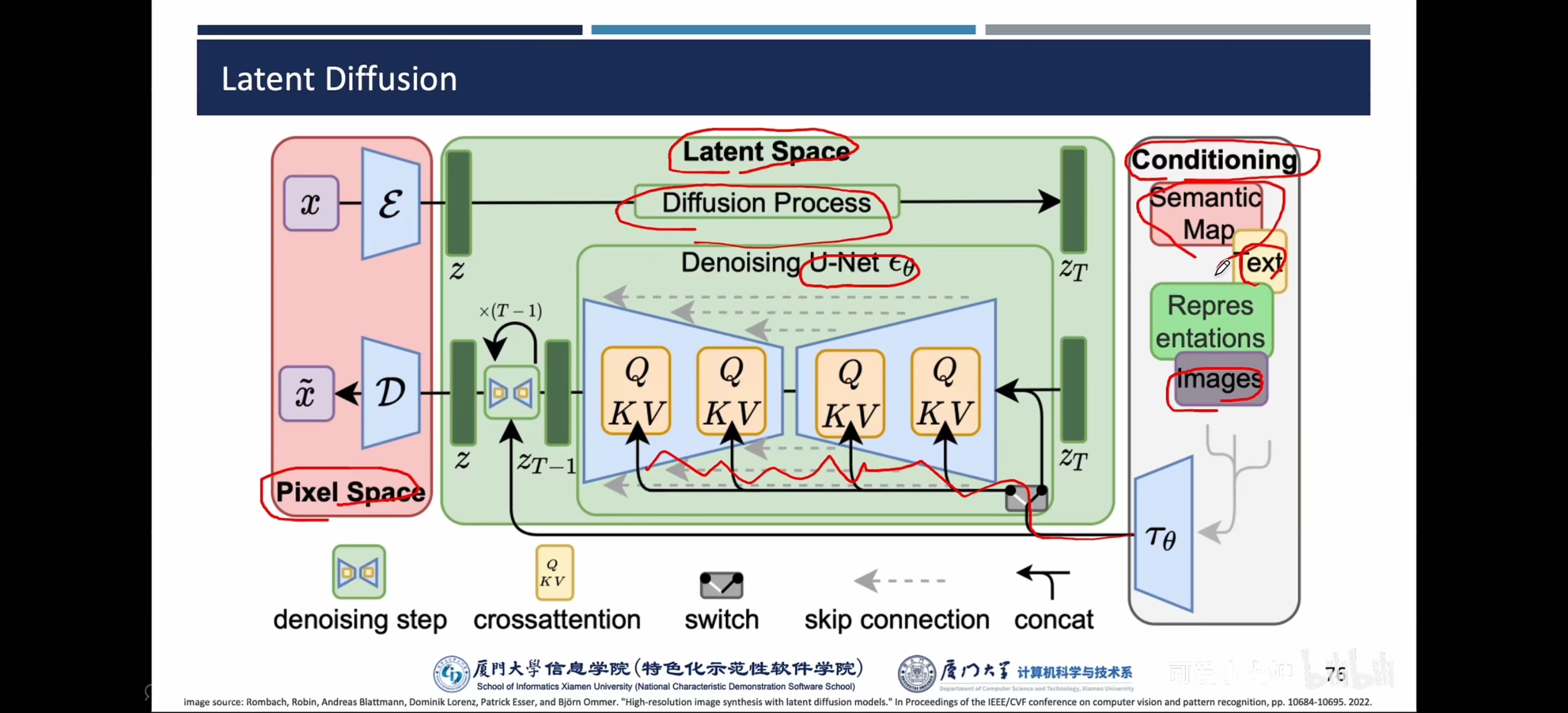
- 应用
- 生成图片+生成视频【输入边缘+文本】
- 风格迁移
- 音乐生成