- State:Agent相对于环境的状态——如网格世界中的状态就是location
 State space:状态空间,所有的状态的集合
State space:状态空间,所有的状态的集合
- Action:每一个状态都有可采取的行动
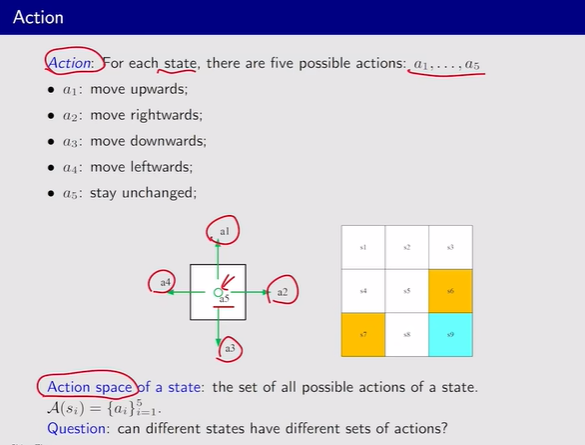 Action space:动作的集合,且不同状态所对应的动作不同,所以A是S的一个函数A(Si)
Action space:动作的集合,且不同状态所对应的动作不同,所以A是S的一个函数A(Si)
- State transition:采取一个动作时,agent的状态发生转移【定义了agent与环境发生交互的行为】

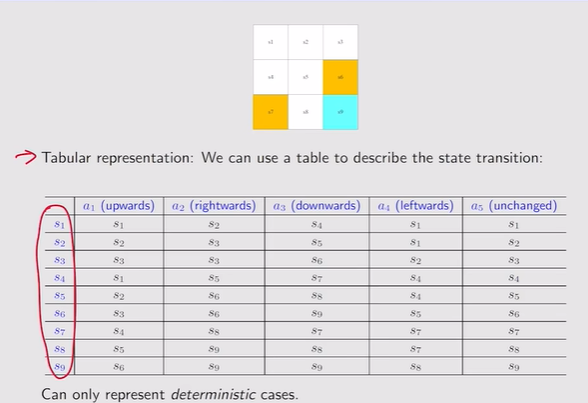 注:表格只能表述行动确定性的情况,随机性的例子需要State transition probability【定义了在当前s状态下,采取动作a,跳到了一个状态s的概率】
注:表格只能表述行动确定性的情况,随机性的例子需要State transition probability【定义了在当前s状态下,采取动作a,跳到了一个状态s的概率】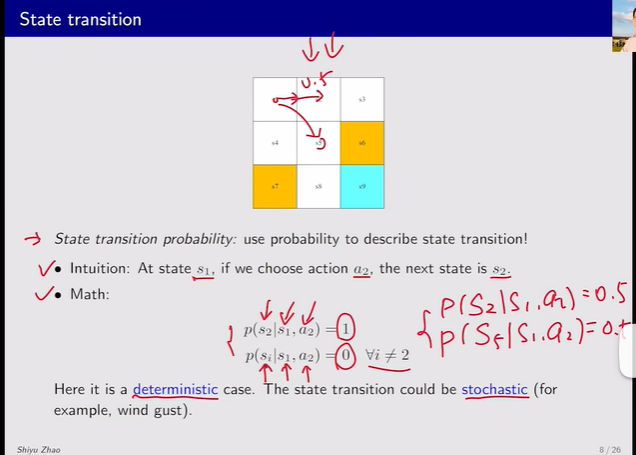
- Policy:策略π——告诉agent在当前状态下应该怎么走【在当前状态下采取动作a的概率,因此对应一个状态采取的所有动作的概率之和为1】,基于策略可以得到路径
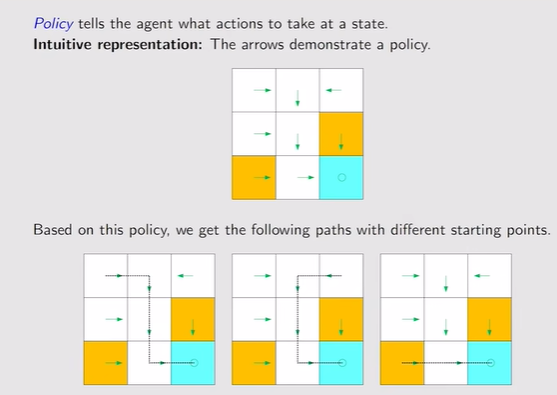
 注:此时策略是确定的,s1状态就只会采取a1的动作
注:此时策略是确定的,s1状态就只会采取a1的动作
- Reward:r为正的代表对行为的鼓励,负的代表对行为的惩罚

 注:reward是引导agent该怎么做,从而实现目标
注:reward是引导agent该怎么做,从而实现目标 注:reward依赖于当前的状态和Action而不是依赖于下一个状态【相同的下一个状态所对应的reward可能不同】
注:reward依赖于当前的状态和Action而不是依赖于下一个状态【相同的下一个状态所对应的reward可能不同】
- Trajectory:State-action-reward链
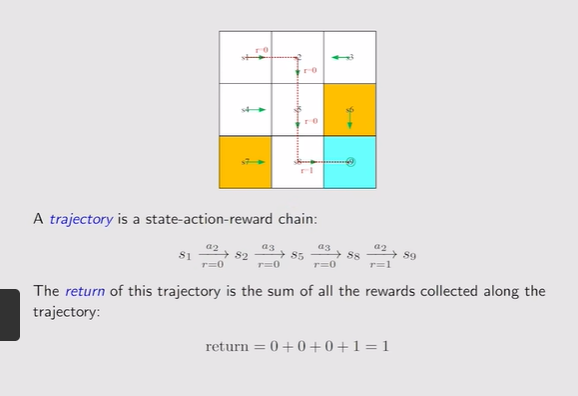 Return:把沿着轨迹的所有reward加起来【Return the greater,policy越好】,可以用于评估一个策略是好还是坏
Return:把沿着轨迹的所有reward加起来【Return the greater,policy越好】,可以用于评估一个策略是好还是坏
- Discounted return:轨迹是无限长的,因此加上折扣因子γ可以有效避免return无限大
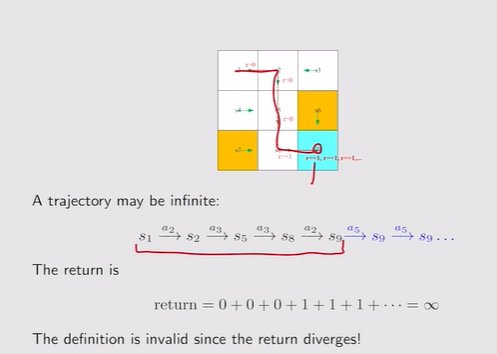
 注:discount rate—γ;γ接近0,那么return会依赖最开始的reward【注重当下】,反之γ趋向1,未来的reward衰减慢,积累起来的return也多依赖未来的reward【考虑未来】
注:discount rate—γ;γ接近0,那么return会依赖最开始的reward【注重当下】,反之γ趋向1,未来的reward衰减慢,积累起来的return也多依赖未来的reward【考虑未来】
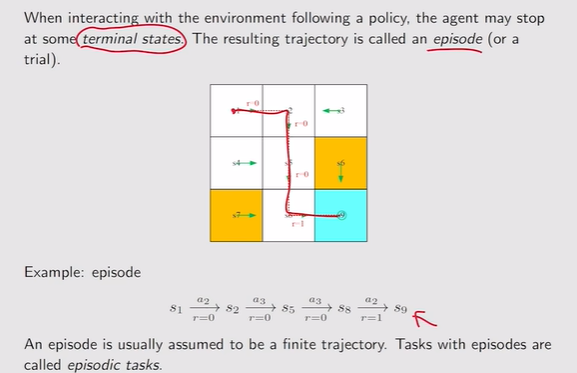
- episode:无terminal state的任务叫做continuing tasks【任务会一直持续下去】

- 马尔科夫链MDP:memoryless property【马尔科夫性:不考虑历史,历史无关性】
 注:Markov——property;decision——policy;process——Sets+Probability
注:Markov——property;decision——policy;process——Sets+Probability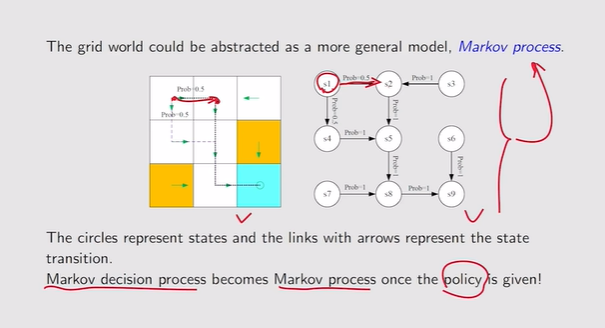 注:decision是确定的,MDP——MP【马尔科夫过程】
注:decision是确定的,MDP——MP【马尔科夫过程】
- 总结:
