- actor与critic:

QAC—The simplest actor-critic
- 定义:θ是策略的参数,θ变策略也变;policy-based+value-based
 注:actor就是θ这个公式,critic就是评估qt这个策略
注:actor就是θ这个公式,critic就是评估qt这个策略
A2C—Advantage actor-critic
- 定义:在QAC中引入新的偏执量baseline来减少估计的方差

 注:引入关于s的偏执b是不会影响梯度的,但baseline对它的方差是有影响的
注:引入关于s的偏执b是不会影响梯度的,但baseline对它的方差是有影响的
- 目标:最优化baseline b使得var(X)最小——这样可以保证采样的时候有更小的误差

 注:Vπ就是qπ的平均
注:Vπ就是qπ的平均

 注:当最优函数用TD error来近似时,只需一个神经网络来近似vt就可。
注:当最优函数用TD error来近似时,只需一个神经网络来近似vt就可。
- A2C算法:

Off-policy
- 定义:利用其它方法所得到的经验来进行策略的更新
- Example: 大数定理



 注:重要性采样的引入
注:重要性采样的引入
- 重要性采样:
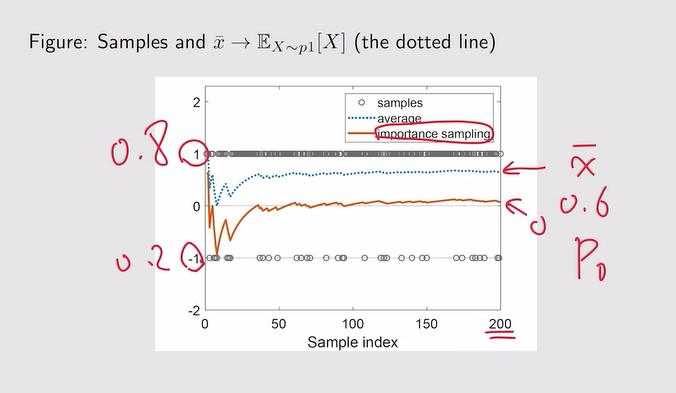




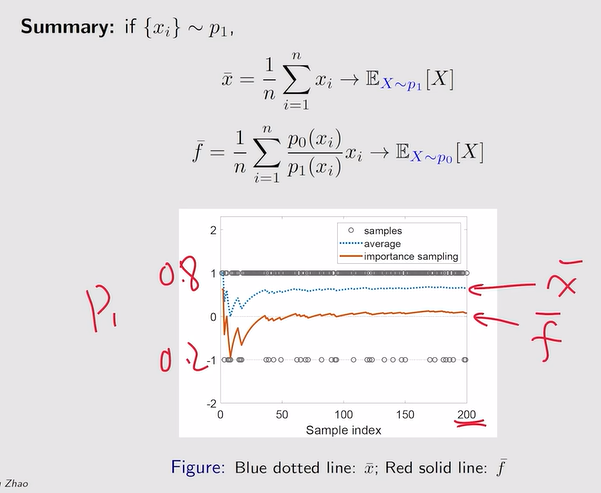
- off-policy—policy gradient:估计p0的期望,但采样是根据p1所得到

- 定理:

 注:探索性消失,因为β是一个固定的值——只有充分利用
注:探索性消失,因为β是一个固定的值——只有充分利用
Deterministic a-c(DPG)
- 和前面的区别:

 注:不确定策略——输出是有限的
注:不确定策略——输出是有限的
- 确定性策略定义:直接输出a,不输出a的概率

- 梯度的计算:确定性策略是天然的off-policy



- 梯度上升:




