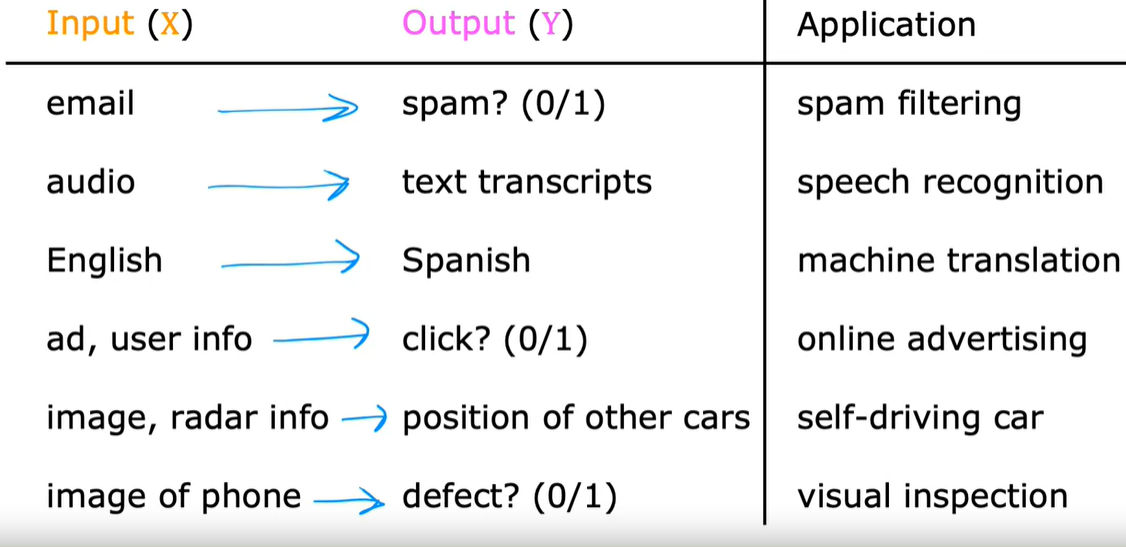
- 机器学习:计算机能够在不经过明确编程的情况下进行学习的研究领域
- 类别
- 监督学习:有标注的,在大量标注数据中进行训练,多用于实际应用中,进步和创新速度也是巨快的
- 非监督学习:数据没有标注,但存在评价的标准或无评价
- 推荐系统
- 强化学习:自己探索从而进行自我尝试
监督学习
- 定义:由X到Y的映射的算法

- 回归:如房价预测是一种特殊的监督学习,他可以用一个数字(房屋的大小),从无限的可能数字中预测一个数字(房屋价格)。
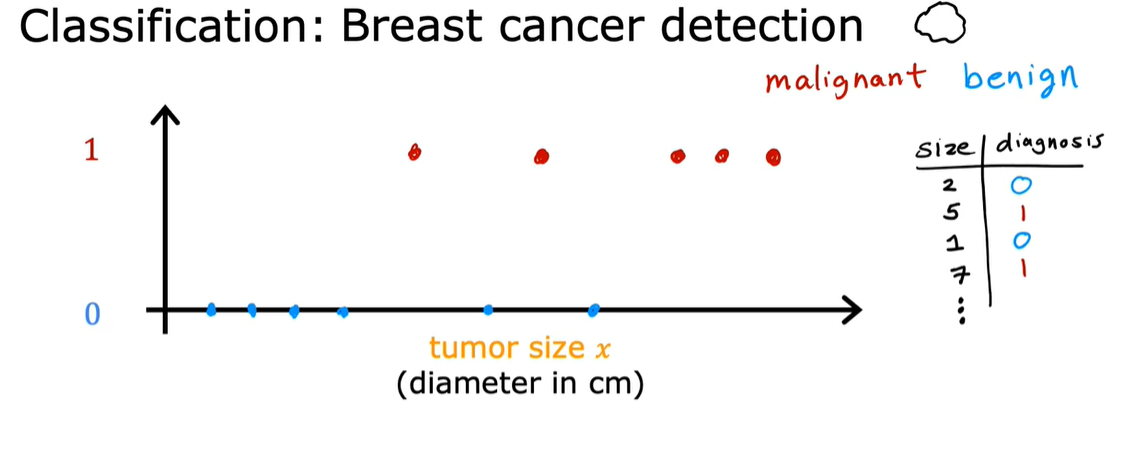
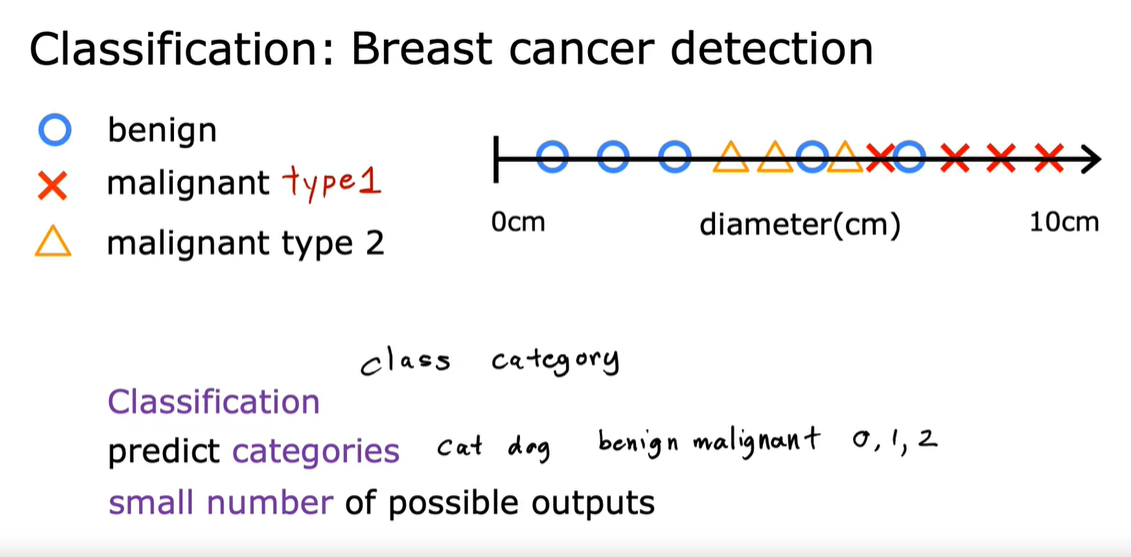
- 分类:分类预测的是类别,可以是非数字,也可以是有限的数字【小猫/小狗、0/1/2】,与回归(回归则试图预测所有可能的数字)不同的是,分类的输出存在两个,即1/0;此外,输入也可以是两个以及两个以上
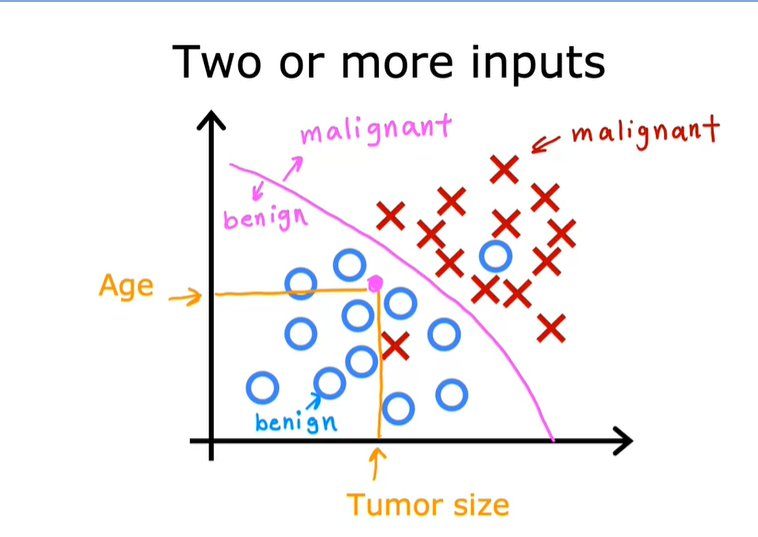 注:当存在两个及两个以上的输入时,需要根据算法以及收集的数据来拟合边界,这样才能更好的进行分类。
注:当存在两个及两个以上的输入时,需要根据算法以及收集的数据来拟合边界,这样才能更好的进行分类。
- 总结:

非监督学习
- 定义:以医学检测肿瘤为例,非监督学习的输入和输出并不匹配,其仅仅只是在数据中找到一些比较有趣的东西,即不想监督算法本身。——发现提供的数据可能存在什么特殊的结构和分布【聚类】
- 聚类算法:获取没有标签的数据,并尝试把他们分组为集群。如新闻的聚类,根据新闻标题相同的词汇,这些新闻会聚集在同一个板块中;+根据DNA微阵列分类人群
 +公司的客户分类
+公司的客户分类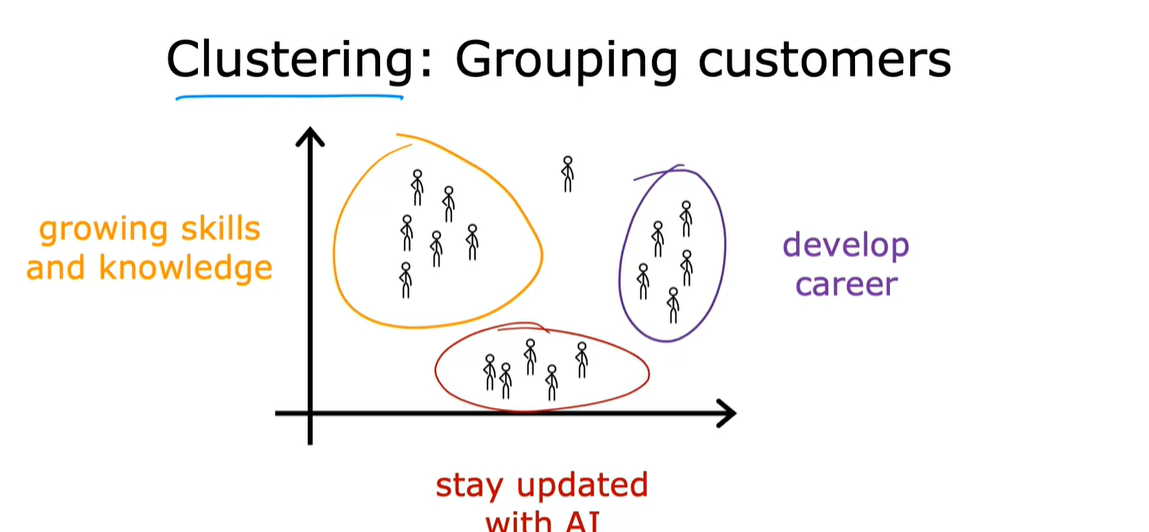
- 异常的检测:检测异常事件,如金融诈骗的检测
- 降维:把一个大的数据集压缩成一个小的多的数据集
- 总结:
