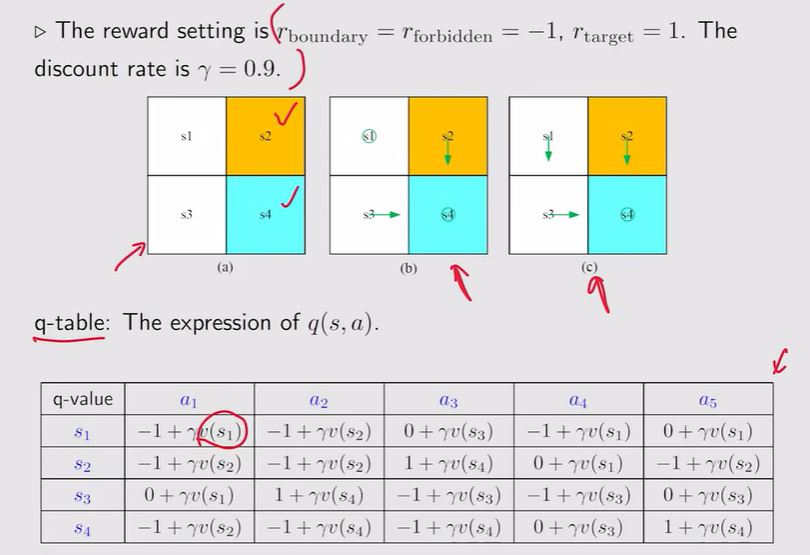
值迭代算法
- value iteration【值迭代】:

 注:这里的Vk不是state value,他只是一个向量、一个值
注:这里的Vk不是state value,他只是一个向量、一个值
- 步骤1:采用贪心策略更新策略

- 步骤2:值迭代——对应q最大的概率是1

- 总结:

策略迭代
- 定义:


- Policy evaluation:

- Policy improvement?


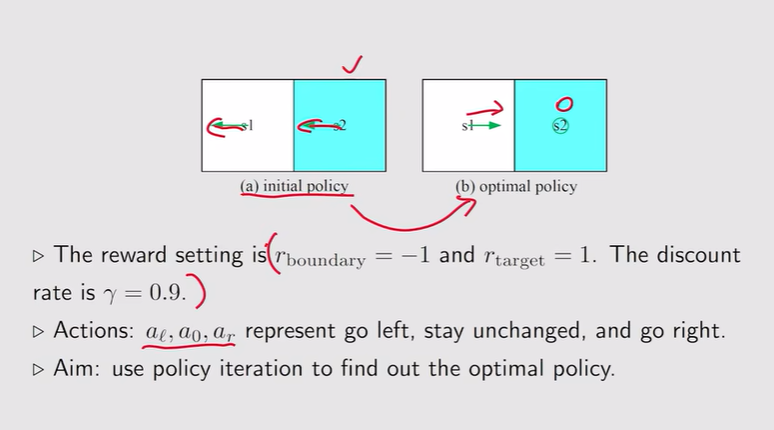
- 策略迭代的具体实现:



- 例:【简单问题】一次迭代就可完成


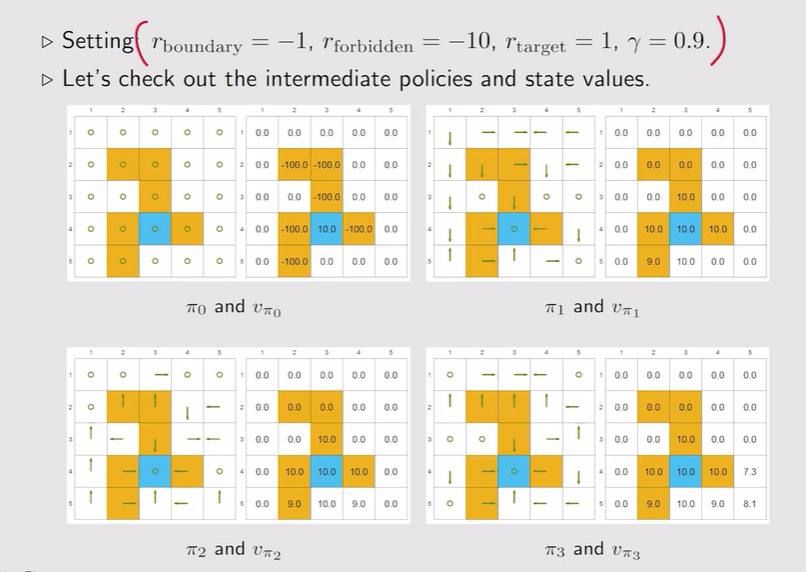
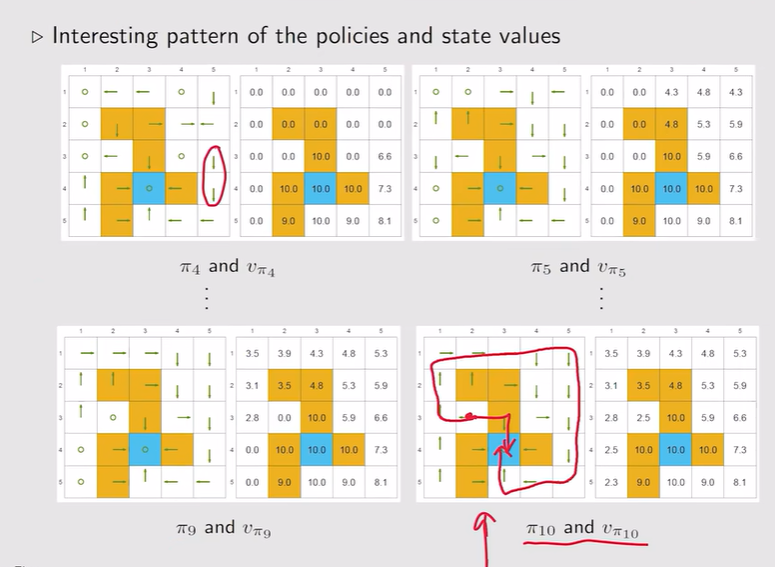
- 【复杂问题】5x5的网格:先接近目标的状态它的策略会先变好,越远离目标的状态会后变好。
Truncated policy iteration algorithm
- 值迭代和策略迭代算法的比较:一个初始化值,从值出发;一个初始化策略,从一个策略出发



- 区别1:Vπ1不等于v1

- Truncated policy iteration:策略评估过程还没结束时就把v提取出来带到下一步的策略更新/策略提升
 注:J=1,就是value iteration;J=∞,就是policy iteration【实际上算不了无穷多步,只需计算两次之间的error足够小就行,最够小就停止迭代】
注:J=1,就是value iteration;J=∞,就是policy iteration【实际上算不了无穷多步,只需计算两次之间的error足够小就行,最够小就停止迭代】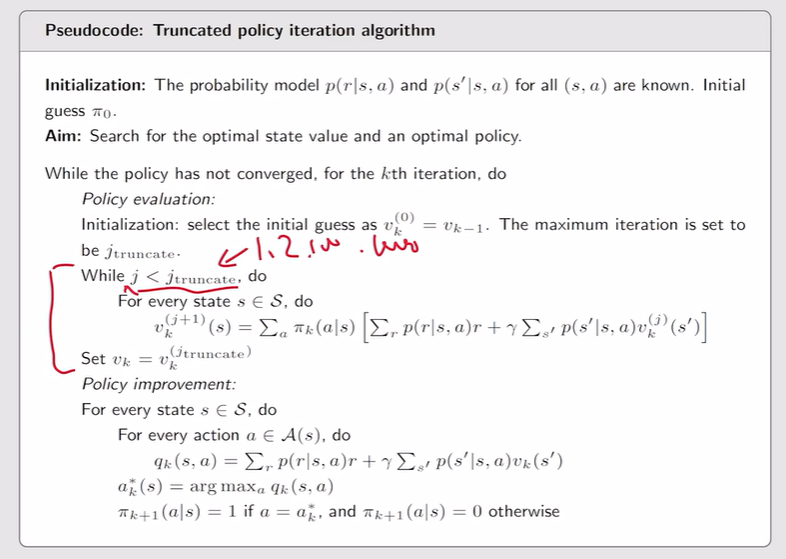 注:设置个迭代次数就行
注:设置个迭代次数就行
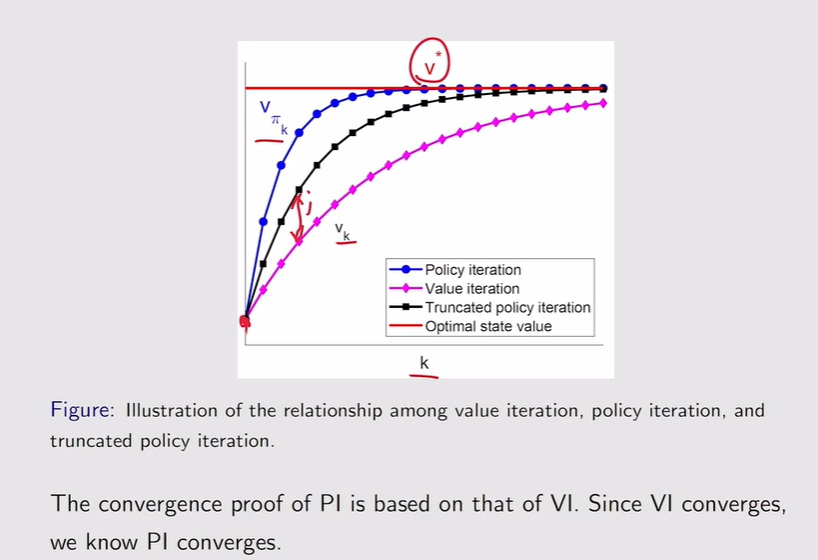 注:收敛性没有改变
注:收敛性没有改变
- 例:策略评估迭代次数的设置——越大迭代次数越小,state value收敛越快,但效果不明显——要选择折中的方案

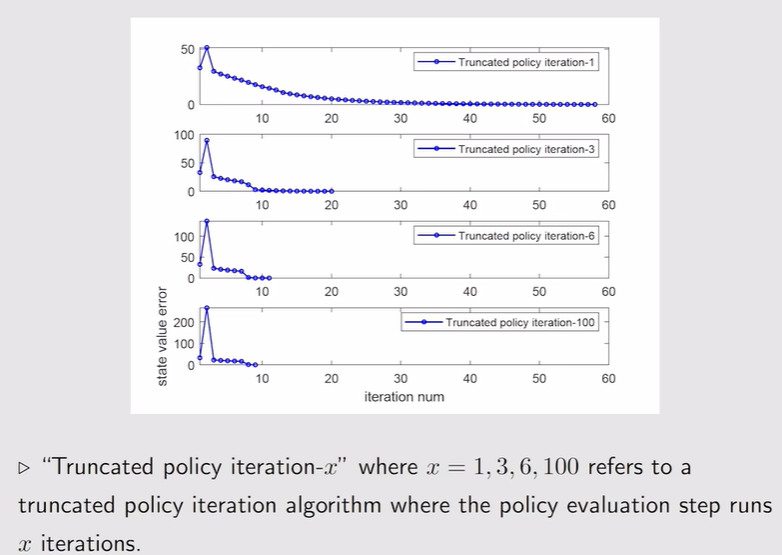
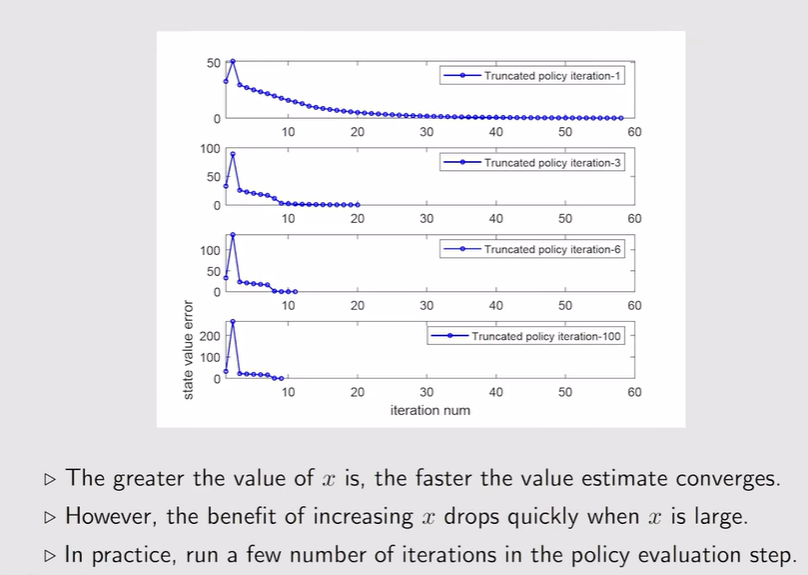
总结