-
背景:J的最小值也有可能有多个!

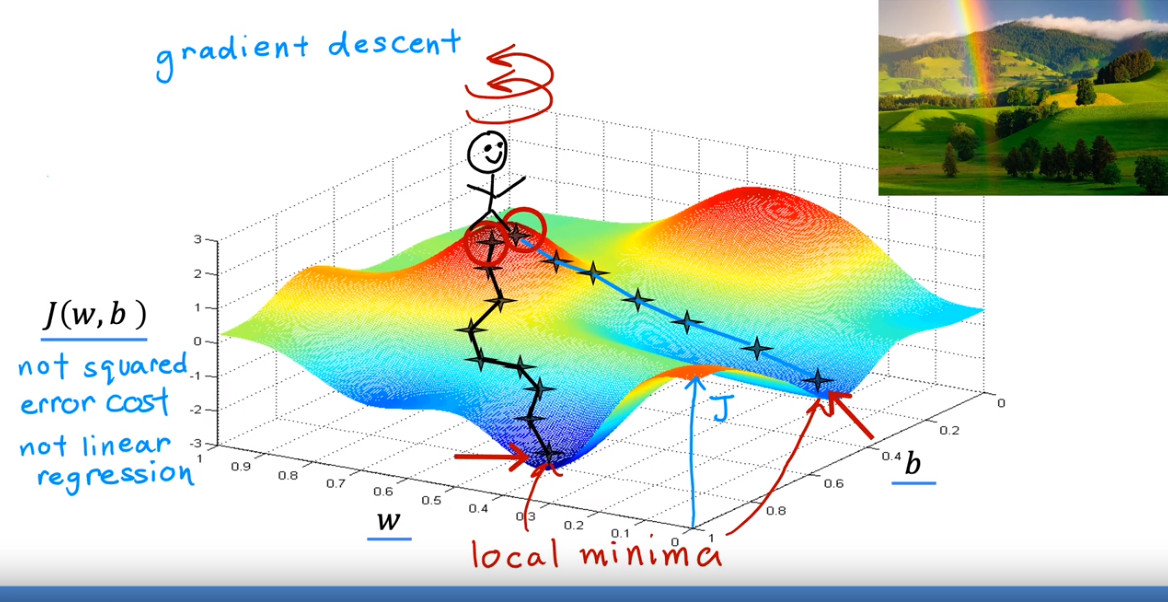 注:初始采取不同的w和b,可能会采取不同的step来步进J函数的最低谷。
注:初始采取不同的w和b,可能会采取不同的step来步进J函数的最低谷。 -
梯度下降算法:w和b最后趋于稳定【收敛】,最好的方法是同步更新

- 关于W——α【学习率:控制下坡的步伐有多大】;J对w的倒数【朝哪个方向迈出第一步,同时和α一起决定下坡步伐的大小】
- 关于b——J对b的倒数
-
梯度下降的倒数:导数意味着斜率,斜率为正,减去正值就往右移动w,导致J变小,反之
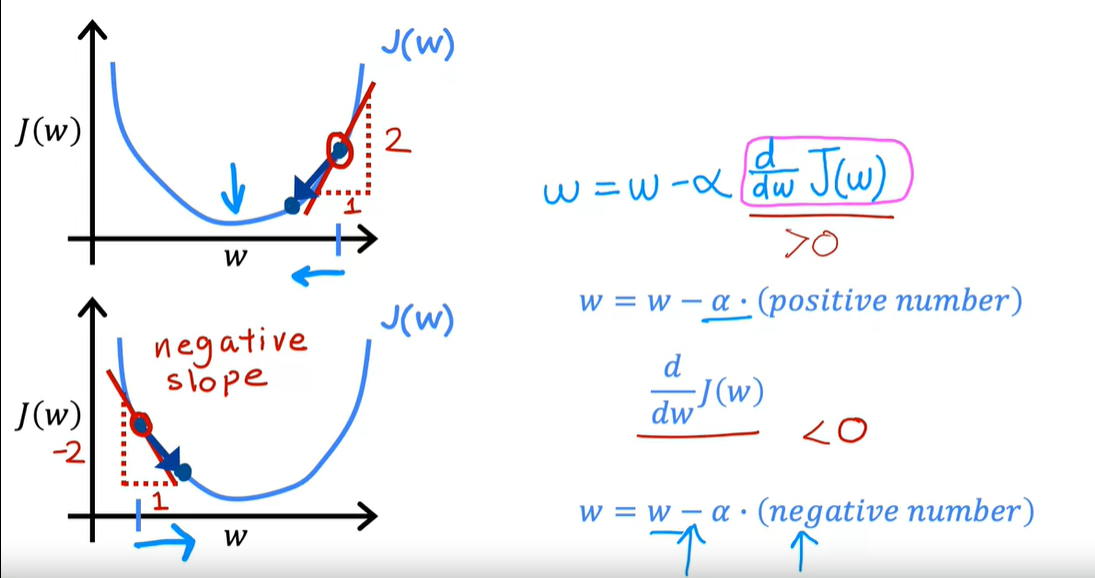
-
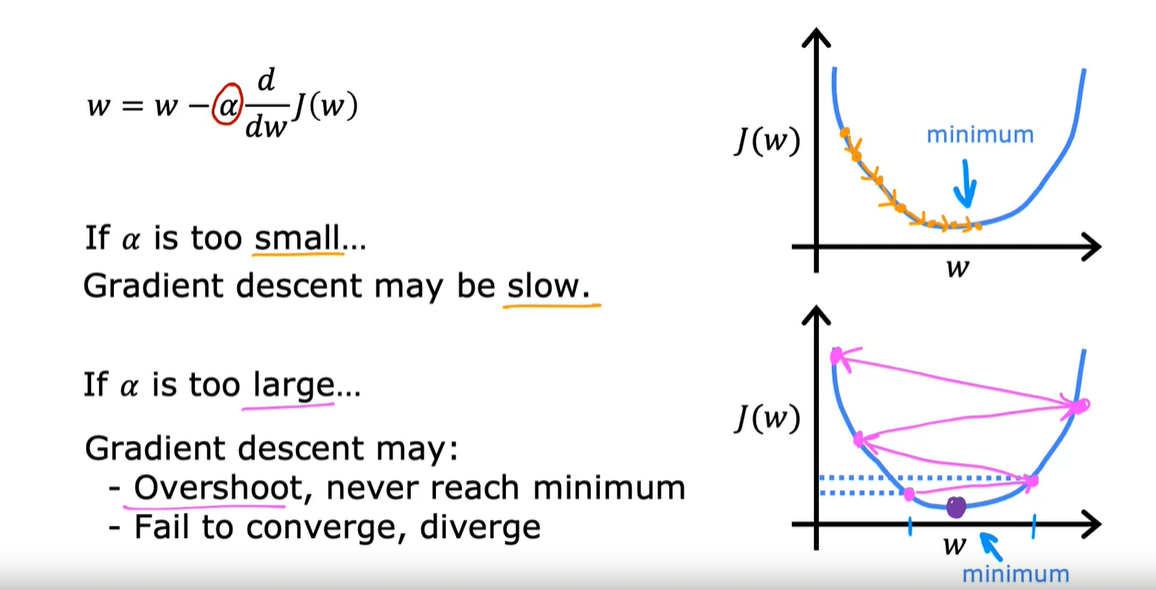
学习率:弱学习率很小,梯度下降的速率会变得慢;学习率太大可能会跨过J的最小值,也可能导致大分叉,越来越偏离J的最小值,导致效果不好
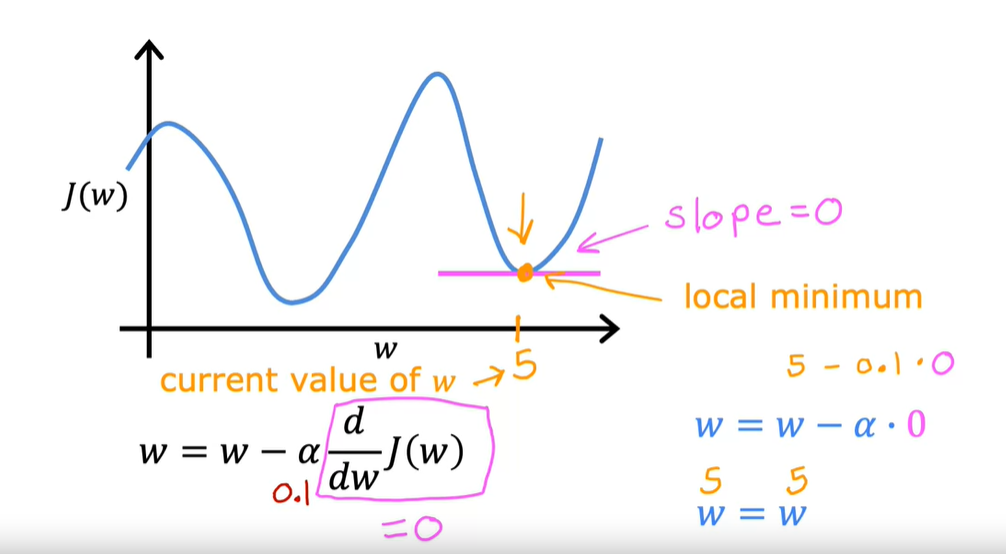 注:如果J达到了局部最小值,那么w将无法进行更新,梯度下降消失
注:如果J达到了局部最小值,那么w将无法进行更新,梯度下降消失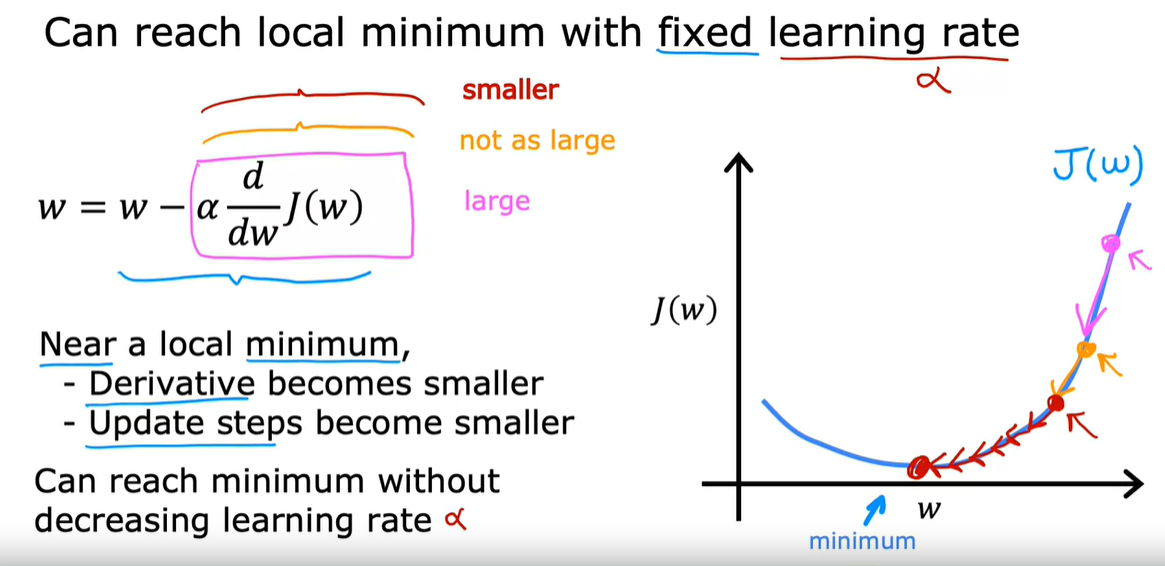
线性回归的梯度下降
- 推导过程:

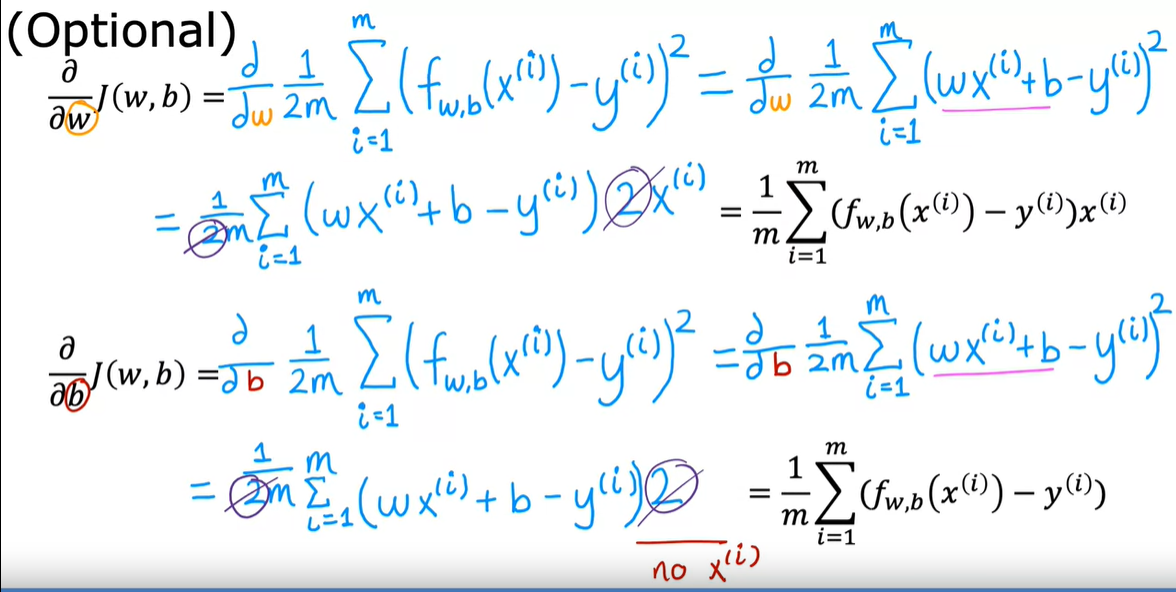
- 算法:注意w和b的更新是同时的

