模型的训练和测试
- 优化算法:梯度下降、基于动量
- 过拟合需要特别关注,其无法通过调整训练步长来优化——调节正则项来优化;除此之外,欠拟合也很重要!

- 关于偏差【刻画了算法本身的拟合能力】、方差【刻画了数据扰动对算法的影响】、噪声【刻画了学习问题本身的难度】、泛化误差【预估值和标签值的偏离程度】:
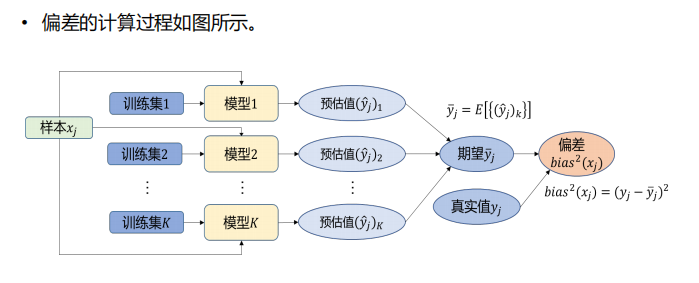
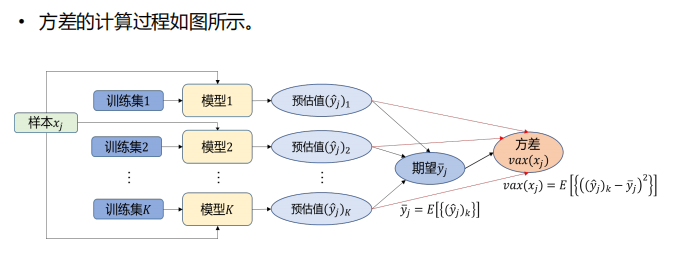
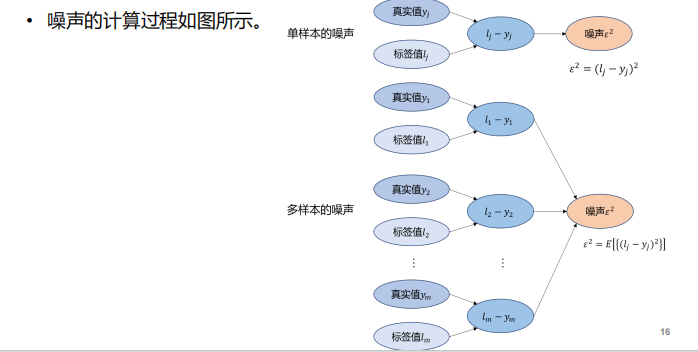
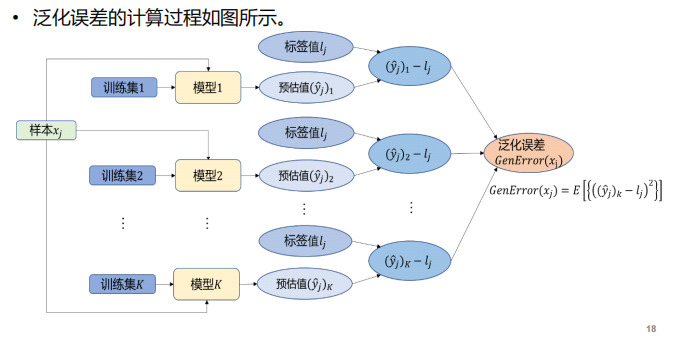

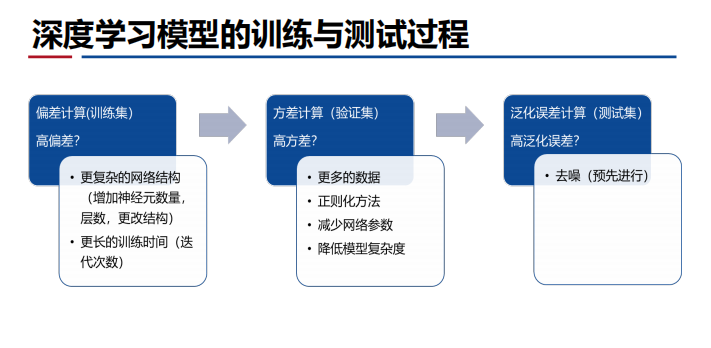
- 噪声和模型无关——真实值和标签之间的计算
参数范数正则化
- 什么是正则化?——参数规模
 注:包含L1、L2两类正则化
注:包含L1、L2两类正则化
数据增强
- 什么是数据增强?对训练数据数量的扩充,利用已有的有限数据产生更多的有效数据。

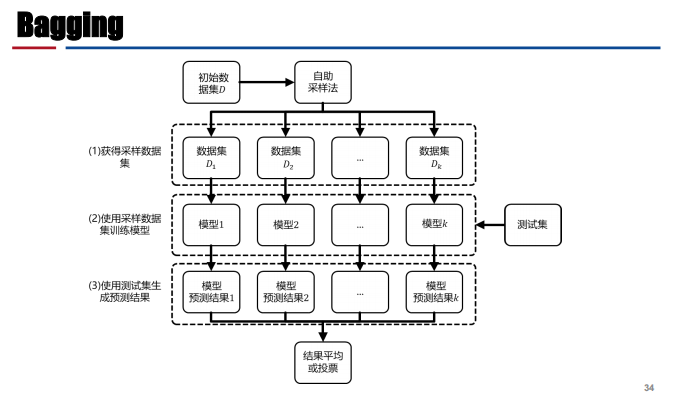
Bagging
- 主要思想:在原始数据集中采样不同的子数据集,然后基于这些子数据集分别训练多个不同的模型,最后将测试样本输入所有模型,将得到的多个结果进行平均或者投票得到测试样本的最终输出。
提前终止
- 定义:

Dropout
- Dropout:减少过拟合的现象,只在训练的时候去掉神经元【(1-p)的概率保留】,测试的时候神经元始终出现,为了让测试集和训练集尽可能分布一致,需要乘概率分布(1-p)

归一化与优化
- 归一化:

- 标准归一化:数据的归一化,非特征的归一化
- 批归一化:解决梯度消失
- 层归一化:自然语言处理/循环神经网络——输入数据长度不一样
- 实例归一化:对图像【图像风格迁移】,且只对空域的信息进行归一化
- 组归一化:对通道分组,每个分组进行归一化
- 权重归一化:把权重拆建成两项,可使用较小的批大小
- 最大最小归一化:

- 优化算法
- 梯度下降法:指示最优值的方向——可能会陷入局部最小值

- 批量梯度下降:稳定性
- 随机梯度下降:可以跳出局部极值点,但梯度方向可能会突变
- 小批量随机梯度下降法
- 动量法:利用历史梯度信息取指数移动平均【梯度方向不会突变】+当前梯度信息——出现振荡时,使得梯度方向稳定
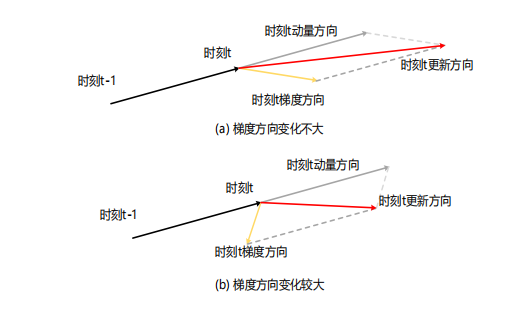
- NAG:走向极值点的步长更长
- 学习率
- AdaGrad:学习率的修改——评价每一个参数更新幅度大小;累积更新量小,给大权重,反之。【但学习率会减小到0,不再更新】
- RMSProp:St-1前面加一个γ权重——避免了学习提前终止,和Ad一样依赖初始学习率
- ADADELTA
- ADAM:引入二阶动量
- NADAM:引入“未来时刻”梯度
- 梯度下降法:指示最优值的方向——可能会陷入局部最小值
5.13——考试【100min】
- 名词解释——PPT内包含
- 解答题——PPT内包含
- 计算题——2道【卷积】
- 设计题——开放【涉及的相关算法,有什么理解,有什么问题,有什么改进思路——目标检测,除了现有方案,还有没有自己的方案】