注意力机制
- 注意力机制:
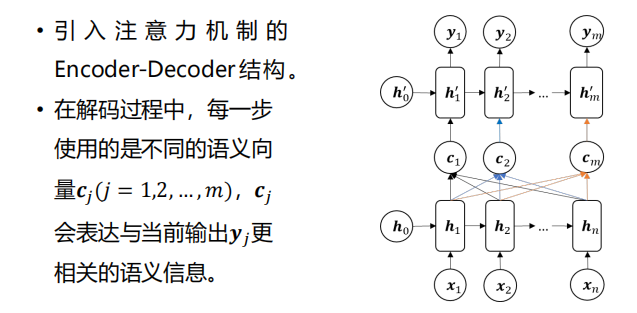
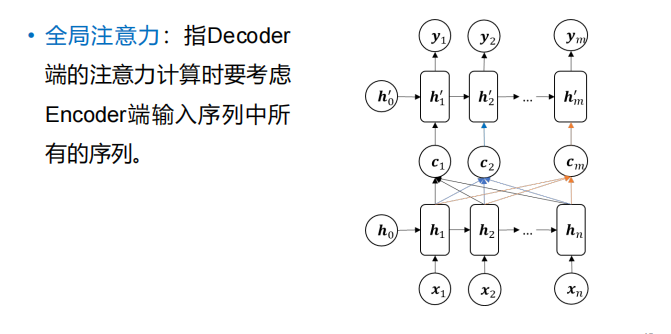
- 全局注意力:
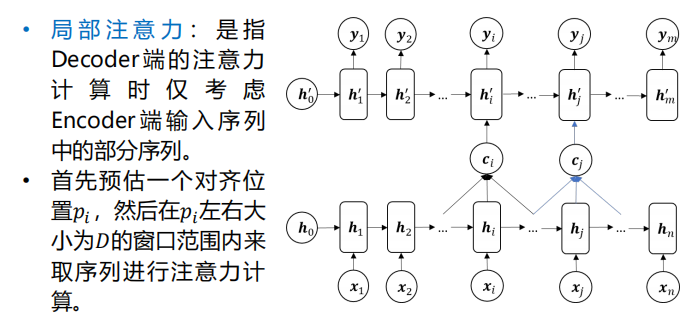
- 局部注意力:
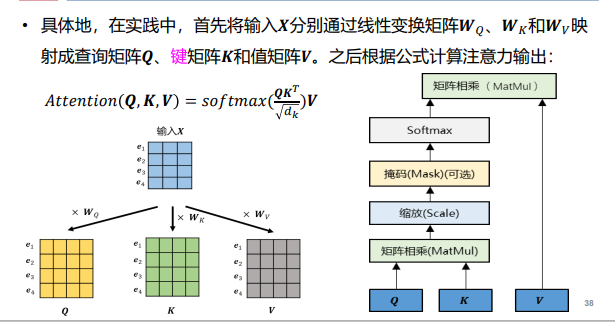
- 自注意力【想要什么就注意什么——与长短时记忆相比,不需要考虑存储之前的状态】:Q、K看方向是否匹配【单词的键与我想要的单词方向是否一致】、V代表单词的重要性【比如主谓宾】
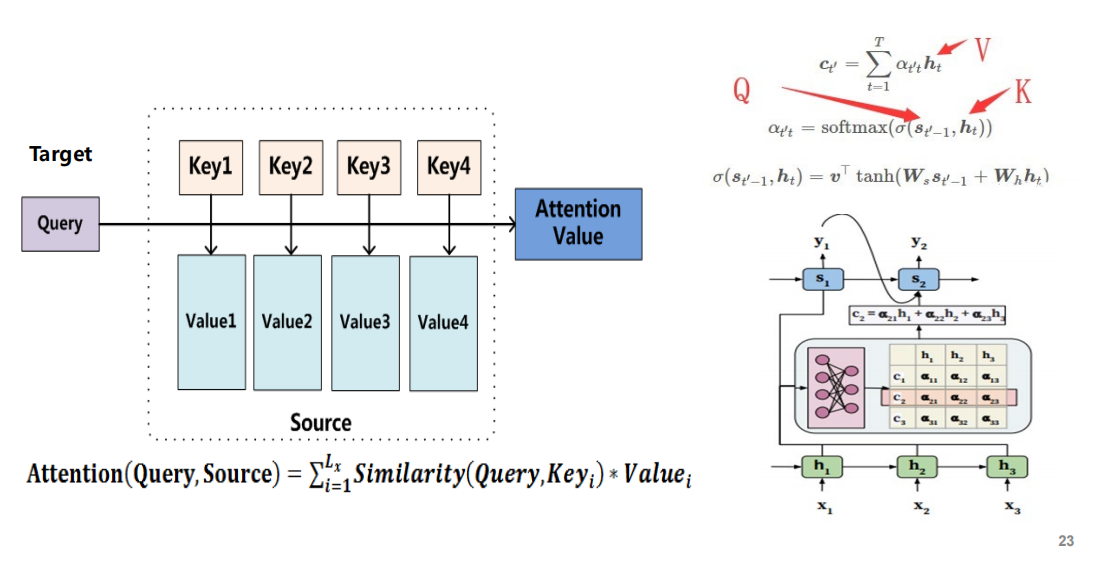
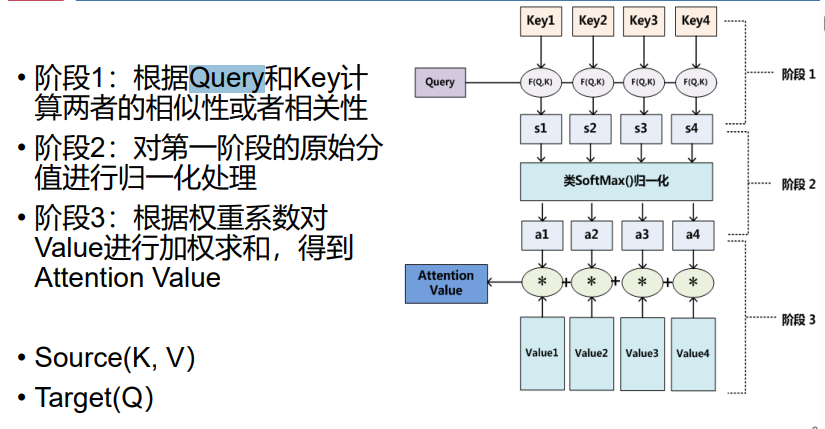
- 三者关系:

- 结构:
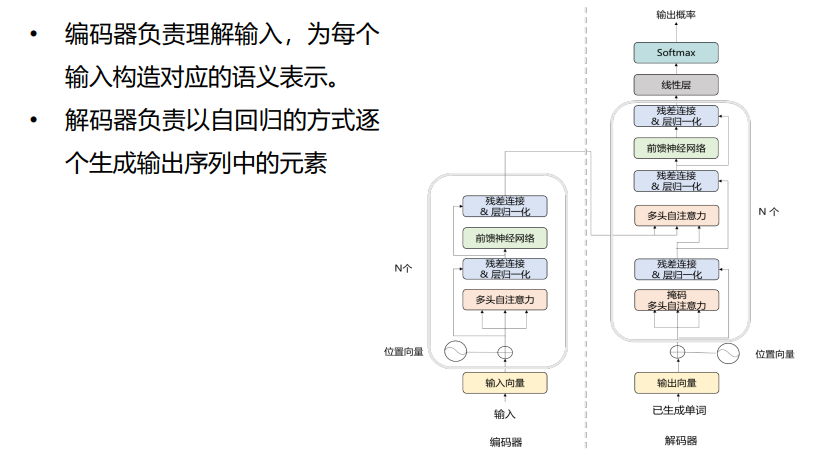 注:解码器的自注意力机制【提取特征】是交叉注意力【编码器的输入+当前解码的输入——检验二者相似性】机制;transformer是并行结构【不同时间点的数据一起输入,对输入的数据不敏感(位置向量区分语序)——可能造成信息泄露——需要进行掩码(单词二只和一有关,盖掉单词3后面的所有)操作】
注:解码器的自注意力机制【提取特征】是交叉注意力【编码器的输入+当前解码的输入——检验二者相似性】机制;transformer是并行结构【不同时间点的数据一起输入,对输入的数据不敏感(位置向量区分语序)——可能造成信息泄露——需要进行掩码(单词二只和一有关,盖掉单词3后面的所有)操作】

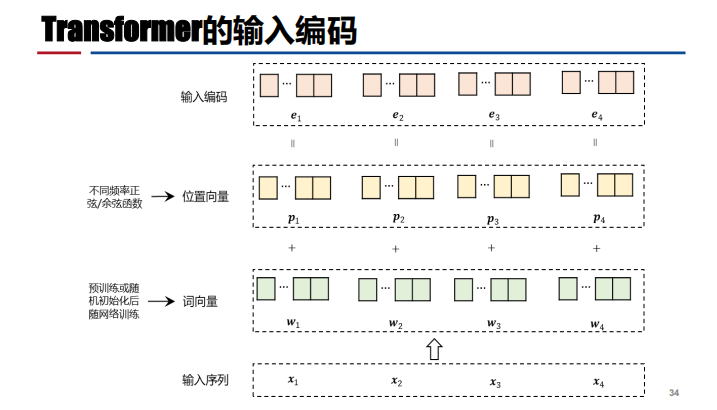
- 自注意力机制:
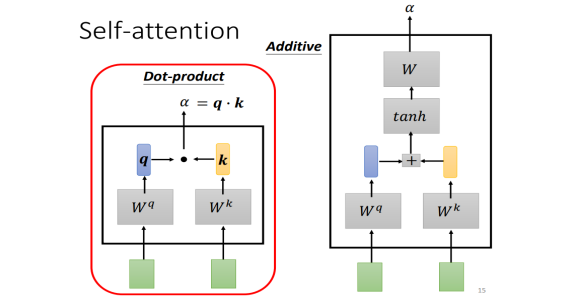

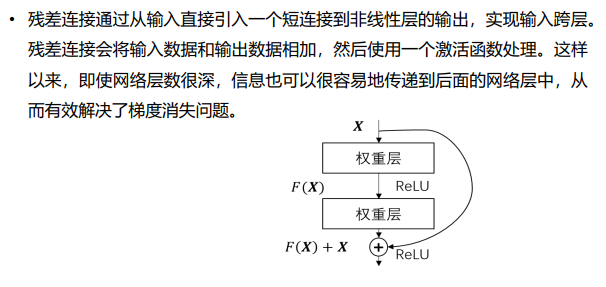
- 残差连接:解决梯度消失
- 层归一化:

- 前馈神经网络:


GPT模型
- 生成式预训练模型【数据量不大时】:对少量样本的微调——将参数调整到更适合下游任务的状态
- 模型实例
- GPT-1:在大规模未标记语料库上训练生成式语言模型,并在下游任务上进行微调以提升下游任务的性能,减轻模型对标记数据的依赖。采用无监督预训练和监督微调相结合的方式,目标是学习一个通用表 示,并将其迁移到更广泛的应用上去。
 注:在大的数据集进行预训练,对前面信息的特征提取,但无法进行文本分类,对未来无法预测,需要进行微调
注:在大的数据集进行预训练,对前面信息的特征提取,但无法进行文本分类,对未来无法预测,需要进行微调 注:无监督损失+监督损失【L1+L2】
注:无监督损失+监督损失【L1+L2】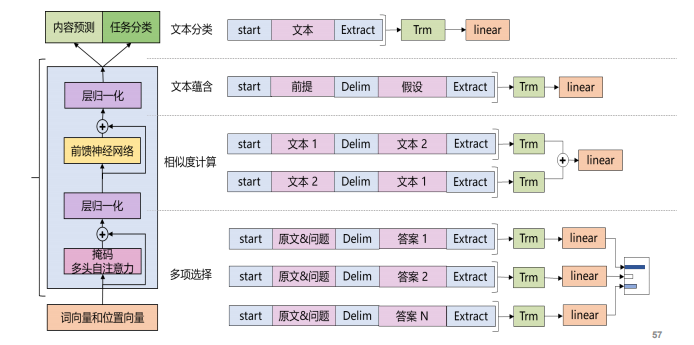
- GPT-2:证明了语言模型可以在零样本(Zero-shot)情况下执行下游任务,而无需任何参数或者架构的修改——思想本质上就是早期的指令微调(Prompt Finetuning)方法,这种做法可以使得模型学习在遇到类似的提示语之后,应该输出什么样的内容。——预训练的内容需要尽可能丰富【相比GPT-1用了更大的数据集和模型】

- GPT-3:使用更少的领域数据,且不经过微调去解决问题。它沿用GPT-2的模型和训练方法,将模型参数大小从GPT-2的15亿个升级到 1750亿。
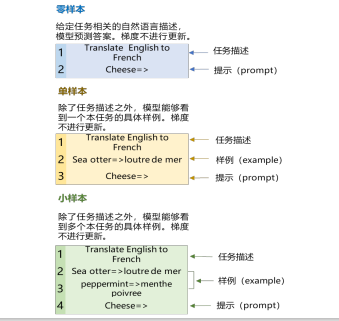

- InsturctGPT:避免输出有害文本——以人类的偏好作为奖励信号来微调GPT模型
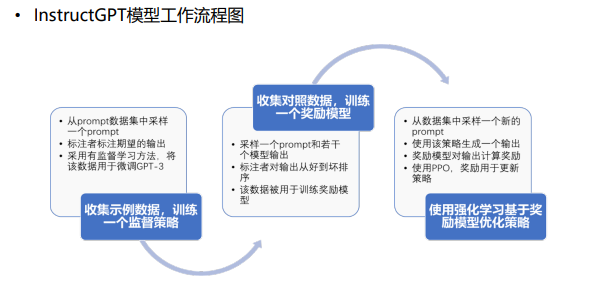

 注:优化基于(偏好-有害)的损失函数【最大化标注人员更喜欢的输出和不喜欢的输出之间的差值】
注:优化基于(偏好-有害)的损失函数【最大化标注人员更喜欢的输出和不喜欢的输出之间的差值】 注:强化学习可能会被偏好带偏——加约束项Dpi
注:强化学习可能会被偏好带偏——加约束项Dpi
- ChatGPT:基于反馈的强化学习

BERT模型
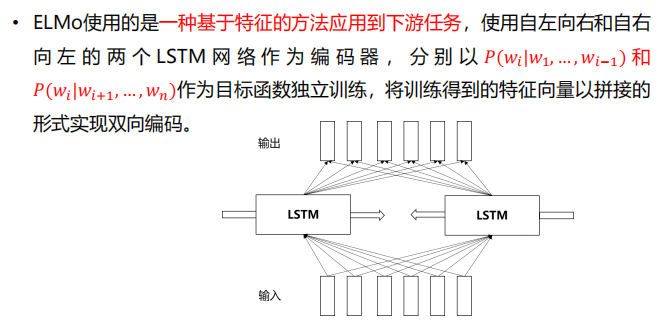
- 简介:基于Transformer的纯Encoder模型,采用双向Transformer编码器作为基础结构,它能够同时利用上下文信息和句子内部信息,提升模型的表达能力。【GPT是单向Transformer】
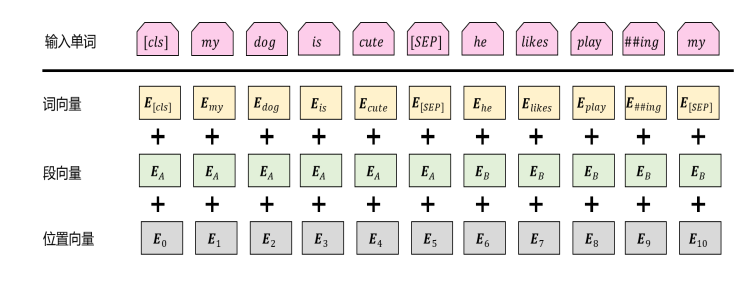
- 输入表示:

- 训练:预训练阶段,BERT使用了掩码语言模型(Masked Language Model, MLM)和下一句预测(Next Sentence Prediction,NSP)两种方法进行预训练。

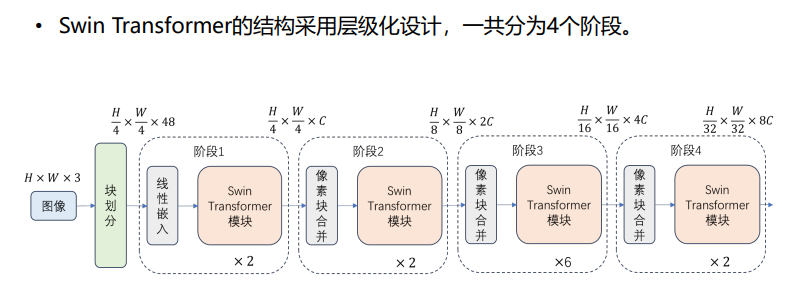
- 简介:种基于滑动窗口机制【没有全局注意能力,窗口变多会导致计算变复杂】、采用层级设计的视觉Transformer,可以作为所有计算机视觉任 务的骨干网络。
- 结构:像素合并【池化,对分辨率进行一次下采样】
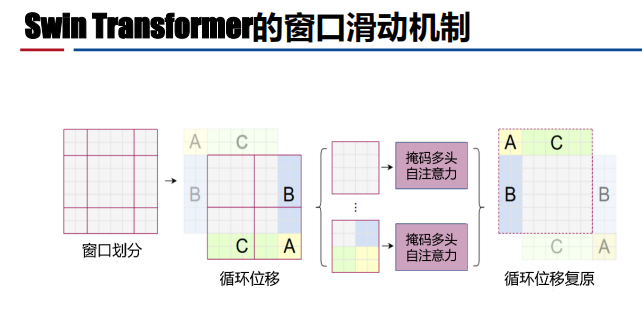
应用:
- 自然语言处理领域
- 机器翻译:

- 机器阅读理解:SG-Net
- 计算机视觉领域:
- 图像分类:ViT模型
- 目标检测:DETR
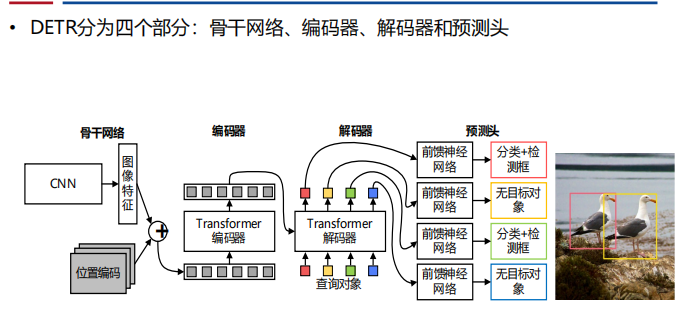
- 多模态领域:
- CNN-Transformer——M2Transformer

- Transformer-Transformer——PureT
