实验设计
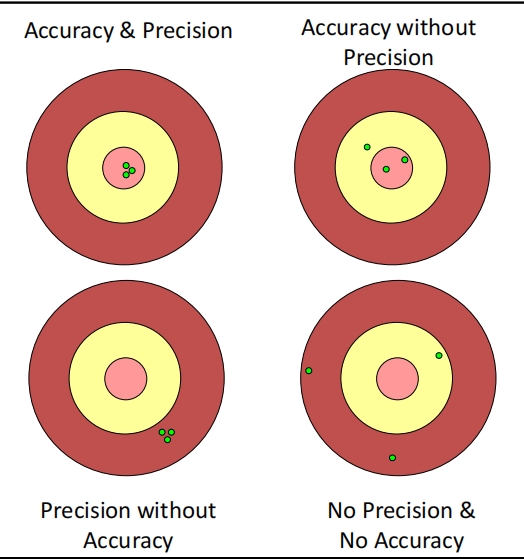
- 精度与准确度的概念:

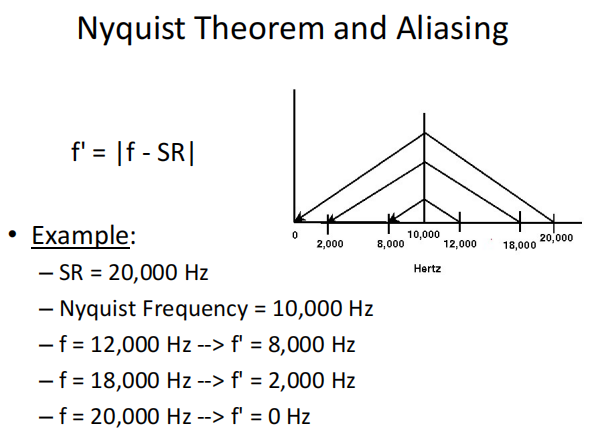
- Nyquist frequency:
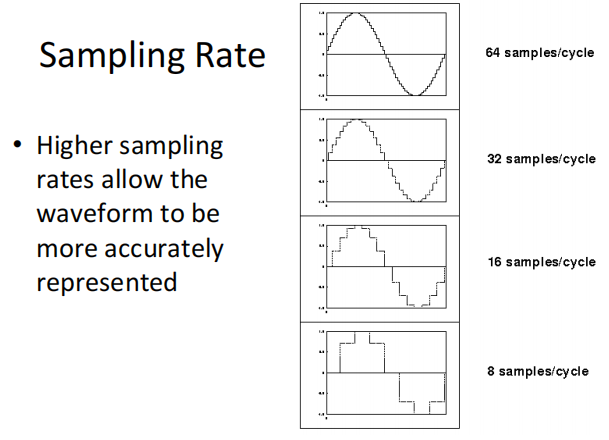
- 波形采样:为了在数字计算机上表示波形,我们需要对波形进行数字化或采样,更高的采样率允许更准确地表示波形——我们只能用数字方式表示高达采样率的一半的频率
- 采样定律:我们只能用数字方式表示高达采样率的一半的频率,超过奈奎斯特频率的频率“折叠”,听起来像更低的频率

- 波形采样:为了在数字计算机上表示波形,我们需要对波形进行数字化或采样,更高的采样率允许更准确地表示波形——我们只能用数字方式表示高达采样率的一半的频率
- 学术不端:

数据统计
- 基本生物统计学:a. 指定你要问的生物学问题。 b.以生物学零假设和替代假设的形式提出这个问题。 c.以统计零假设和替代假设的形式提出这个问题。 d.确定哪些变量与该问题相关。 e.确定每个变量都是什么类型的变量。 f.设计一个实验来控制或随机化混杂变量。 g.选择要使用的最佳统计检验方法(变量的数量、变量的种类、对参数假设的期望拟合,以及待检验的假设)h。如果可能的话,进行一个功率分析,以确定一个良好的实验样本量。i.做这个实验。j.检查这些数据,看看它是否符合您所选择的统计检验的假设(测量变量检验的正态性和同方差)。如果没有,那就选择一个更合适的测试方法。k.应用您选择的统计测试,并解释结果。l.有效地传达你的结果,通常是用一个图表或表格。
- 大数定律:一个描述了多次进行相同实验的结果的定理。根据该规律,从大量试验中得到的结果的平均值应该接近期望值,并且随着更多试验的进行,将会趋于更接近期望值。
- 中心极限定理:具体来说,无论原始分布是什么,只要满足一定的条件(比如有限方差),当样本量足够大时,样本均值的分布就会近似于正态分布。
- 总结:
 注:1.大数定律——收敛到均值;2. 中心极限定律——以一个正态分布收敛到均值 3. t分布——小样本,且类似于正态分布【用t分别构建置信区间】
注:1.大数定律——收敛到均值;2. 中心极限定律——以一个正态分布收敛到均值 3. t分布——小样本,且类似于正态分布【用t分别构建置信区间】 - 常用的测量变量:
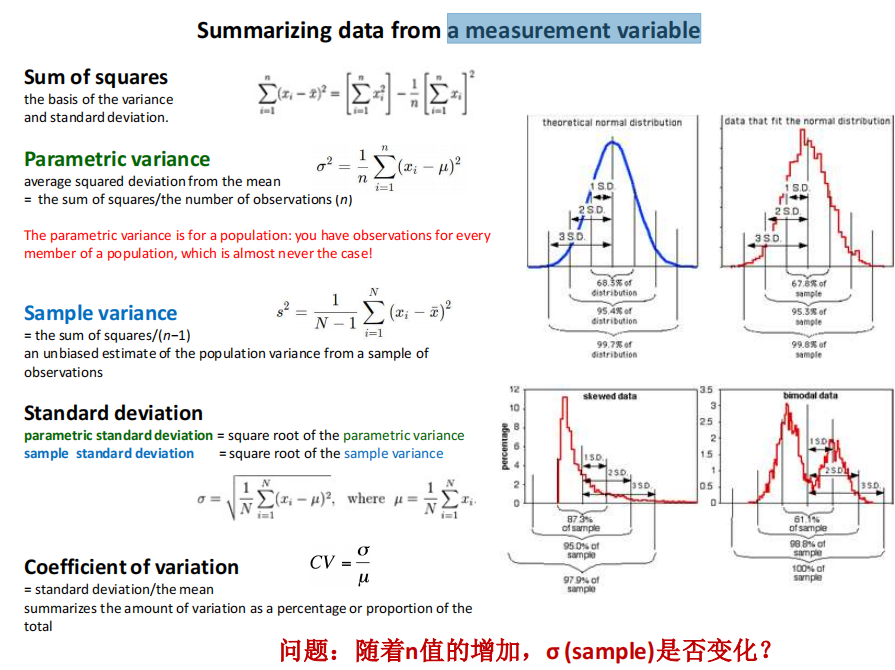
 注:随着n的增加,标准差会一定程度减小
注:随着n的增加,标准差会一定程度减小
- 描述统计与推断统计:本质上,描述性统计陈述了来自人口的事实和已证实的结果,而推理统计则分析抽样来预测更大的人口。
- 描述性:描述性统计侧重于一个数据集的特征,确定性水平非常高。异常值和其他因素可能被排除在总体调查结果之外,以确保更高的准确性,但计算往往不那么复杂得多,可以得出可靠的结论。
- 推断:推断统计数据被设计用来检验一个因变量,即被研究的总体参数或结果,并且可能涉及几个变量。
- 效应大小和置信区间:实际用效应大小来说明,不能说显著有区别。

- Bootstrapping:

- 关键点:参数、置信区间、标准误、假设检验做法、一类错误/二类错误(样本量与犯错的关系)、贝叶斯、bootstrapping
 注:贝叶斯
注:贝叶斯 注:样本量的重要性
注:样本量的重要性
 注:一类错误与二类错误
注:一类错误与二类错误
基因编辑——可见细胞生物学笔记
基因编辑定义:基因编辑技术是人为的对靶基因进行定点改造,实现特定DNA的定点敲除、敲入、替换等突变,最终下调或上调基因的表达,以使细胞获得新表型的一种技术。
- RNA干扰
- 化学诱变:

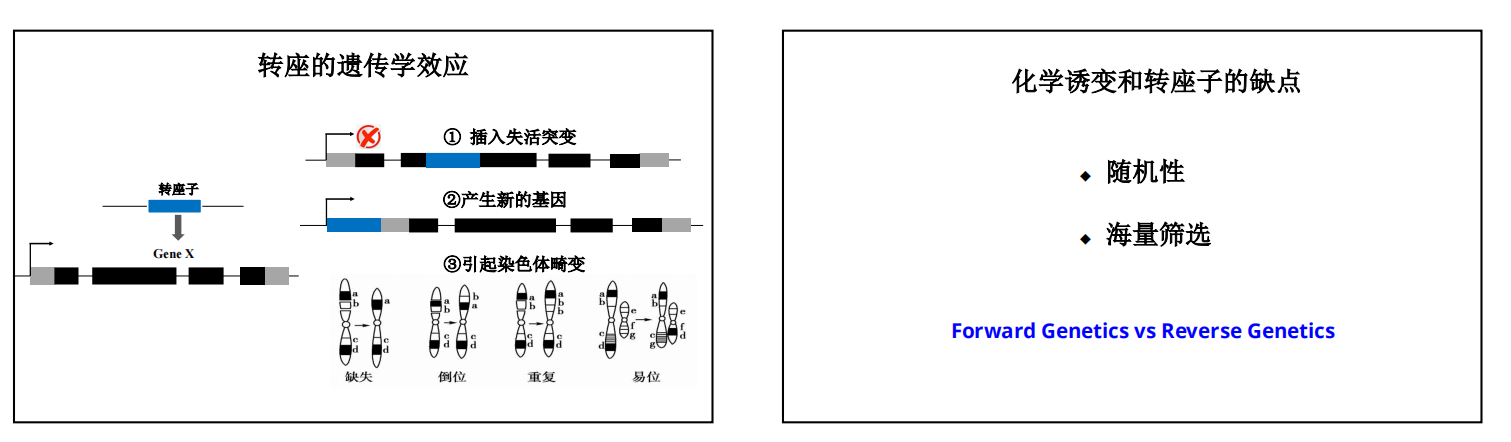
- 转座子:转座子是基因组中一段可移动的DNA序列,可以通过切割、重新整合等一系列过程从基因组的一个位置“跳跃”到另一个位置,改变原有基因的结构和排序,从而产生突变。
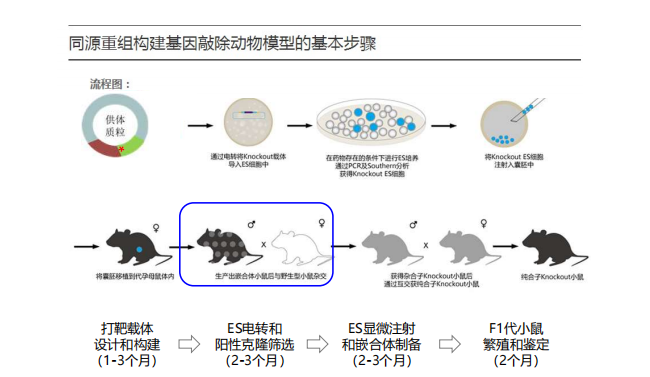
- 同源重组:
- Crispr-cas9:
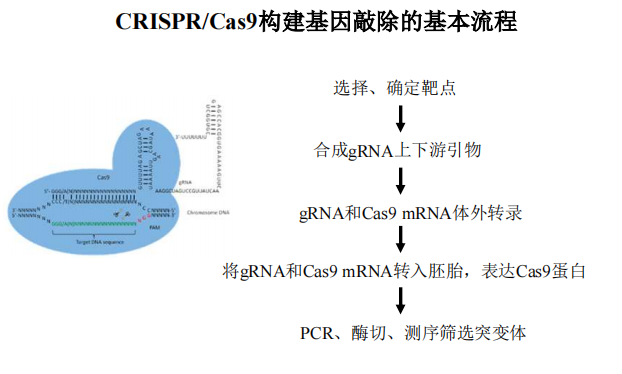
 注:回答了为什么筛杂合突变体!
注:回答了为什么筛杂合突变体!
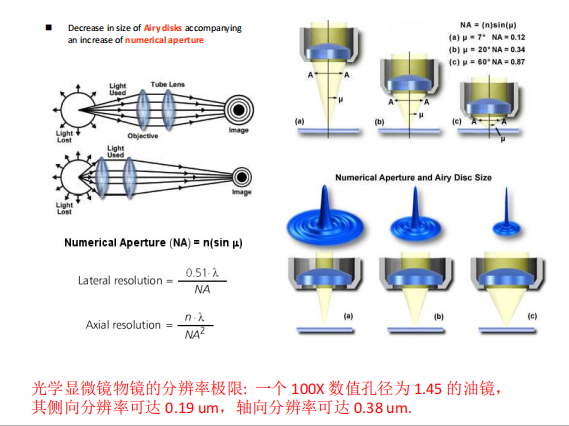
显微镜
- 分辨率:

- NA

- 光学分辨率的极限: